Ingest streaming records and metadata
In Imply Polaris, you can ingest both event data and event metadata from an Apache Kafka® topic or a Kinesis stream.
An event, or record, consumed from either of these contains metadata. For Kafka topics, this includes the key, Kafka timestamp, and any headers sent with the event. For a Kinesis stream, this includes the ApproximateArrivalTimestamp that corresponds to when a stream receives and stores a record and the partition key.
This topic shows you how to ingest streaming event data and its corresponding metadata.
Ingest Kafka metadata
To parse Kafka metadata for ingestion, follow these steps:
-
In the Parse data stage of creating an ingestion job, select the format of the event data in the Input format drop-down menu.
-
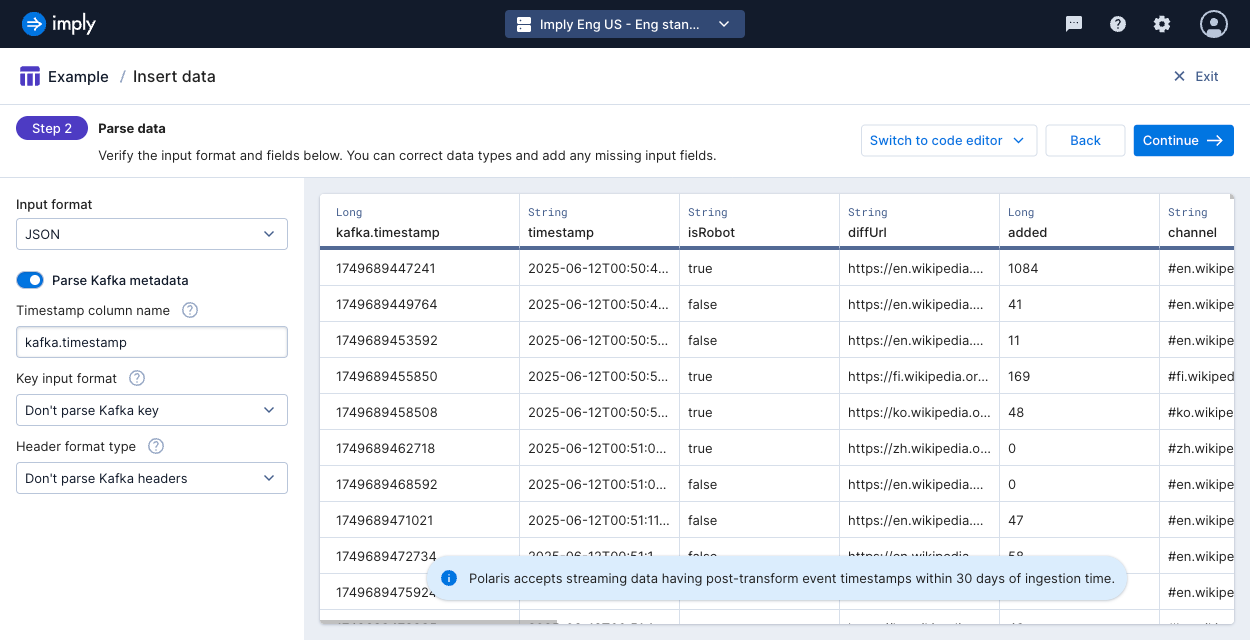
Click the Parse Kafka metadata toggle.
-
Polaris displays fields specific to the Kafka metadata format:
-
Timestamp column name: A name to use for the Kafka timestamp. This name becomes the input field name that you can use in mappings.
-
Key input format: Format to use to parse the Kafka key. When you select a format, Polaris displays the option to set the Key column name. This becomes the name of the input field that you can use in input expressions. See Supported formats for Kafka keys for more information.
-
Header format type: Character encoding to use to parse data from the Kafka headers. When you elect to parse Kafka headers, you can define the header column prefix. Polaris prepends this prefix to the name of the Kafka header. For example, you have a Kafka header named
Header-1and you use the default prefix,kafka.header.. In your input expressions, you would refer to the input field namekafka.header.Header-1.
-
-
Select Continue to continue onto the Map source to table stage. If you use the Kafka timestamp as your input to the primary timestamp,
__time, define the input expression asMILLIS_TO_TIMESTAMP("kafka.timestamp"). If you use a non-default timestamp column name, update the value in the function. Verify that the Kafka timestamp is within 30 days of ingestion time. -
Click Start ingestion to begin the ingestion job.
Supported formats for Kafka keys
If you store the key as a plain string, use the CSV input format.
To parse text out of a string key, select the regex format to capture the target data using regular expressions.
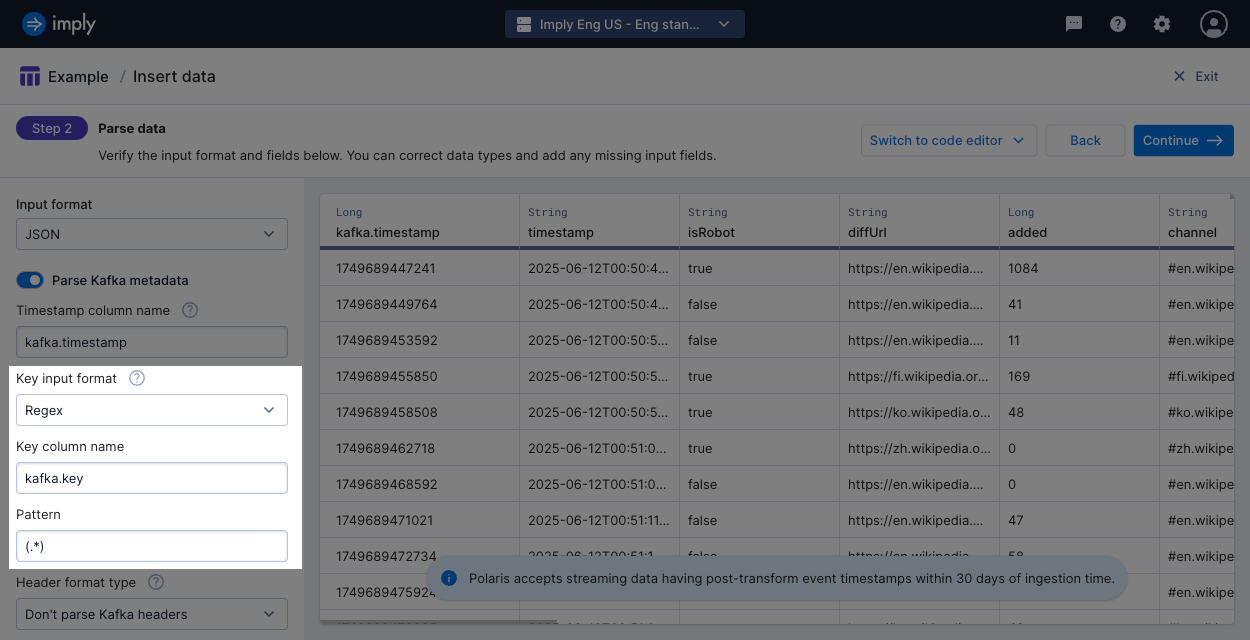
Regardless of the format selected, if your key gets parsed into multiple columns, Polaris only ingests the data from the first column.
You can also specify use a schema registry connection to parse the key data. To do so, use the Jobs API to define the key format. For more details and an example, see Ingest Kafka records and metadata by API.
Ingest Kinesis metadata
-
In the Parse data stage of creating an ingestion job, select the format of the event data in the Input format drop-down menu.
-
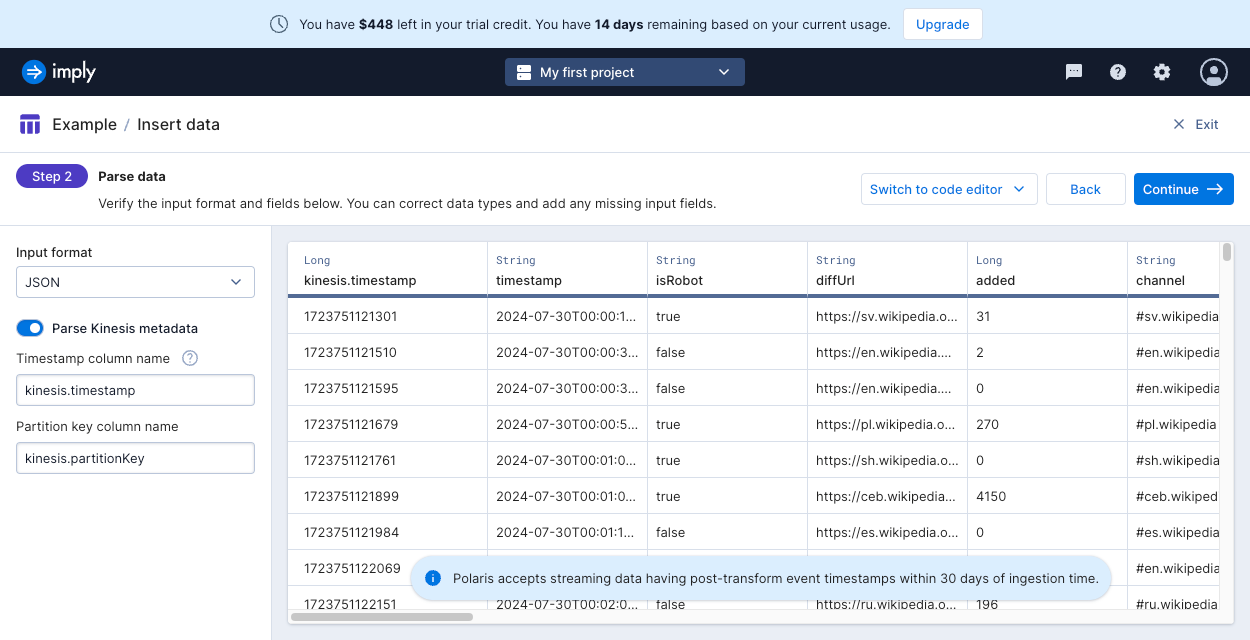
Click the Parse Kinesis metadata toggle.
-
Polaris displays fields specific to the Kinesis metadata format:
- Timestamp column name: A name to use for the Kinesis timestamp. This name becomes the input field name that you can use in mappings. Defaults to
kinesis.timestamp. - Partition key column name: A name to use for the Kinesis partition key. The partition key identifies which shard a message belongs to.
- Timestamp column name: A name to use for the Kinesis timestamp. This name becomes the input field name that you can use in mappings. Defaults to
-
Select Continue to continue onto the Map source to table stage. If you use
kinesis.timestampas your input to the primary timestamp,__time, define the input expression asMILLIS_TO_TIMESTAMP("kinesis.timestamp"). If you changed the timestamp column name, update the value in the function. Verify that the Kinesis timestamp is within 30 days of ingestion time. -
Click Start ingestion to begin the ingestion job.
Learn more
You can also configure the settings for ingesting Kafka records and associated metadata using the API. For more information, see the topics for Kafka format and Kinesis format.
For details on creating connections, see the following topics: