Multiple topics per connection
Connections in Imply Polaris describe the source of data from which to ingest into tables. When the source of your data comes from an Apache Kafka® streaming platform, including managed Kafka services such as Confluent Cloud, you can create a connection associated with multiple Kafka topics. You cannot use multi-topic connections with Amazon Kinesis. An ingestion job from a multi-topic Kafka connection ingests data from all topics within the scope of the connection.
This topic describes multi-topic connections in Polaris. Before continuing, you should be familiar with the concepts of creating connections and ingestion jobs.
Prerequisites
The following details must be identical for all topics associated with a multi-topic connection:
- Bootstrap servers
- Authentication credentials
- Data format
- Schema registry, if applicable
- Offset position to consume
Create a multi-topic connection
To create a multi-topic connection, check the box for Use regex for topic name underneath Topic name.
In Topic name, specify a regular expression pattern to identify topic names.
For example, topic[0-9]* matches topic1 and topic23 but not topicAB.
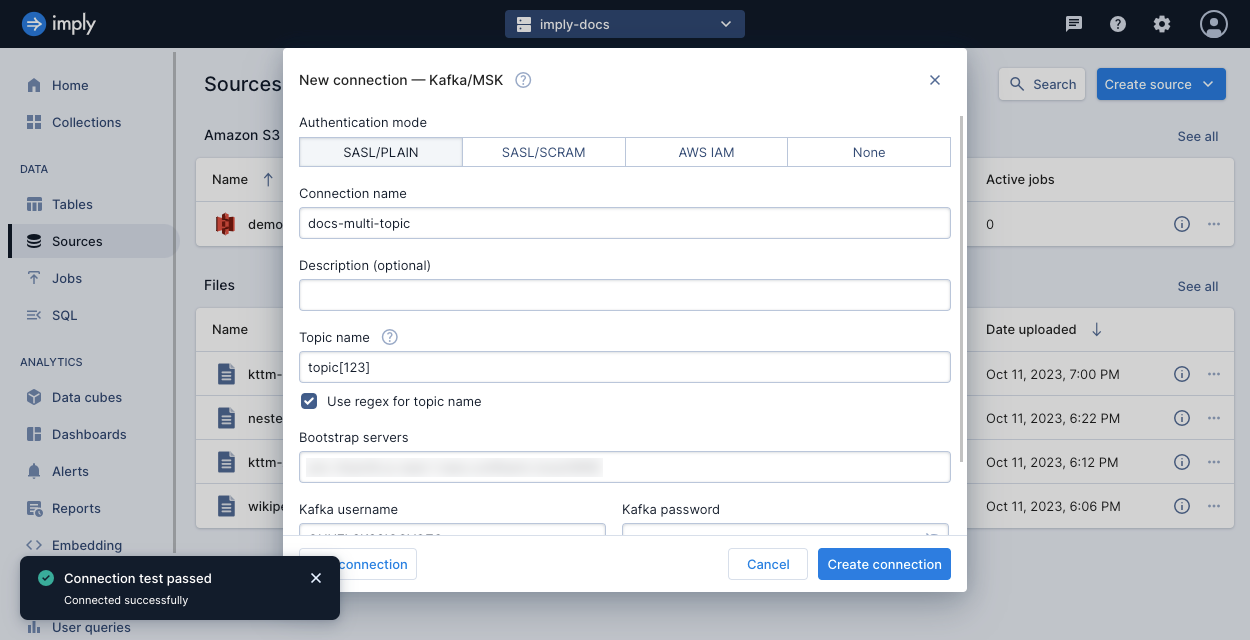
When you test the connection, Polaris seeks to the beginning and end offsets from all the partitions for all applicable topics. If the test connection fails, verify the bootstrap servers and authentication credentials. A test connection may also fail if any of the topics contain an invalid partition.
Ingest from a multi-topic connection
This example describes how Polaris treats multi-topic connections during ingestion. To follow along, create three topics and push data to each topic, following the given structure and examples:
-
Events in
topic1have the propertiesevent_time,sessionId, andbrowseTime{"event_time": "2023-10-16T00:00:00.000Z", "sessionId": "S834761", "browseTime": 609.001} -
Events in
topic2have the propertiesevent_time,browseTime,discount, andpurchaseTotal{"event_time": "2023-10-17T00:00:00.000Z", "browseTime": "3045.987", "discount": 48.42, "purchaseTotal": 2054.13} -
Events in
topic3have the propertiesevent_time,discount, andpurchaseTotal{"event_time": "2023-10-18T00:00:00.000Z", "discount": 4.59, "purchaseTotal": 688.70}
-
Create a multi-topic connection. For the topic name, enter
topic[123]. -
Start a new ingestion job using the multi-topic connection as the source. In the Parse data step, select the toggle to Parse Kafka metadata. Polaris then includes a column called
kafka.topicthat lists the name of the topic that produced the row of data.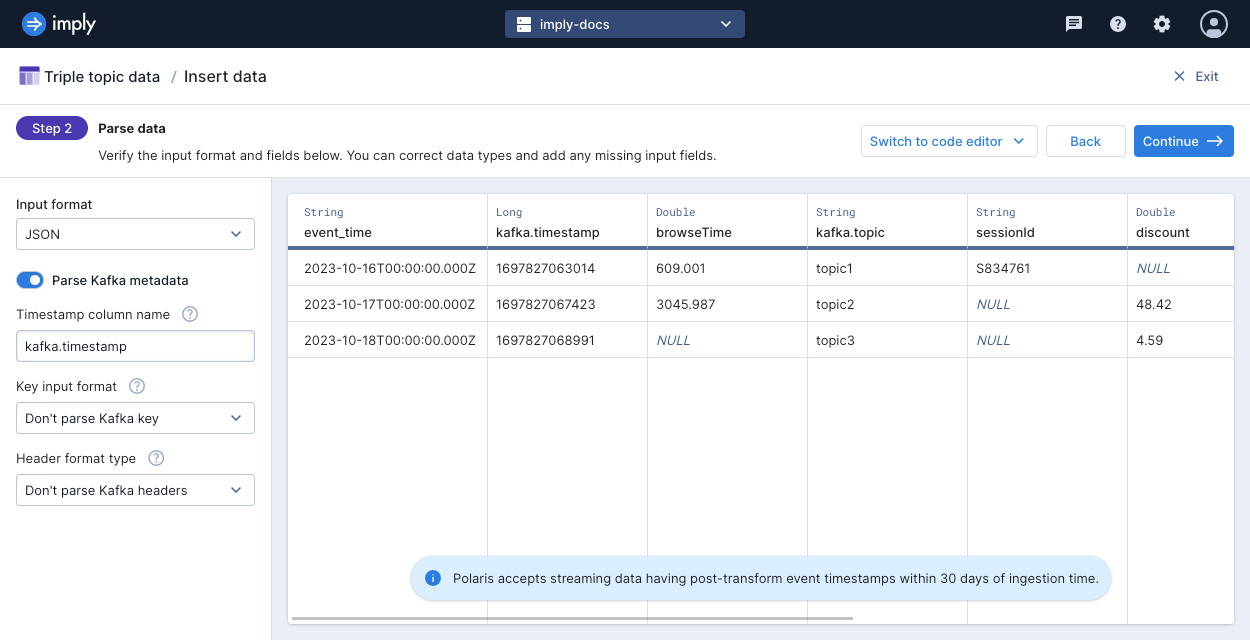
-
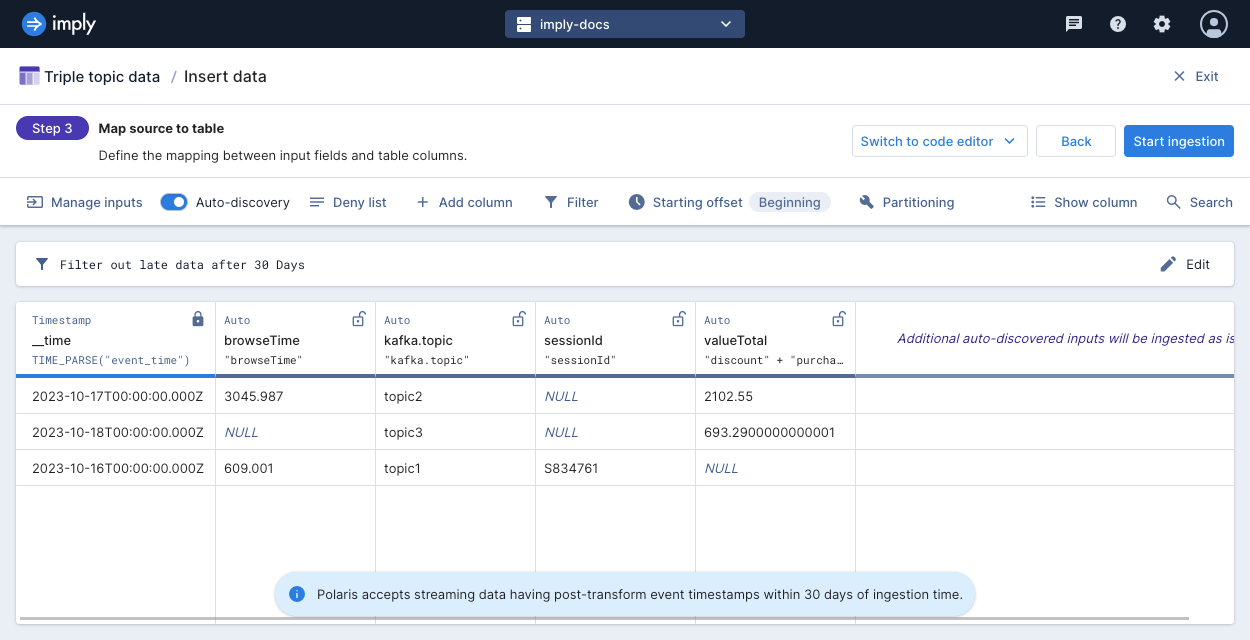
In the Map source to table step, apply the following mappings for the given table columns:
__timemapped toTIME_PARSE("event_time")browseTimemapped to"browseTime"kafka.topicmapped to"kafka.topic"sessionIdmapped to"sessionId"valueTotalmapped to"discount" + "purchaseTotal"
You can remove extra columns from the Kafka metadata or that are already used in another mapping.
-
Click Start ingestion to launch the ingestion job.
-
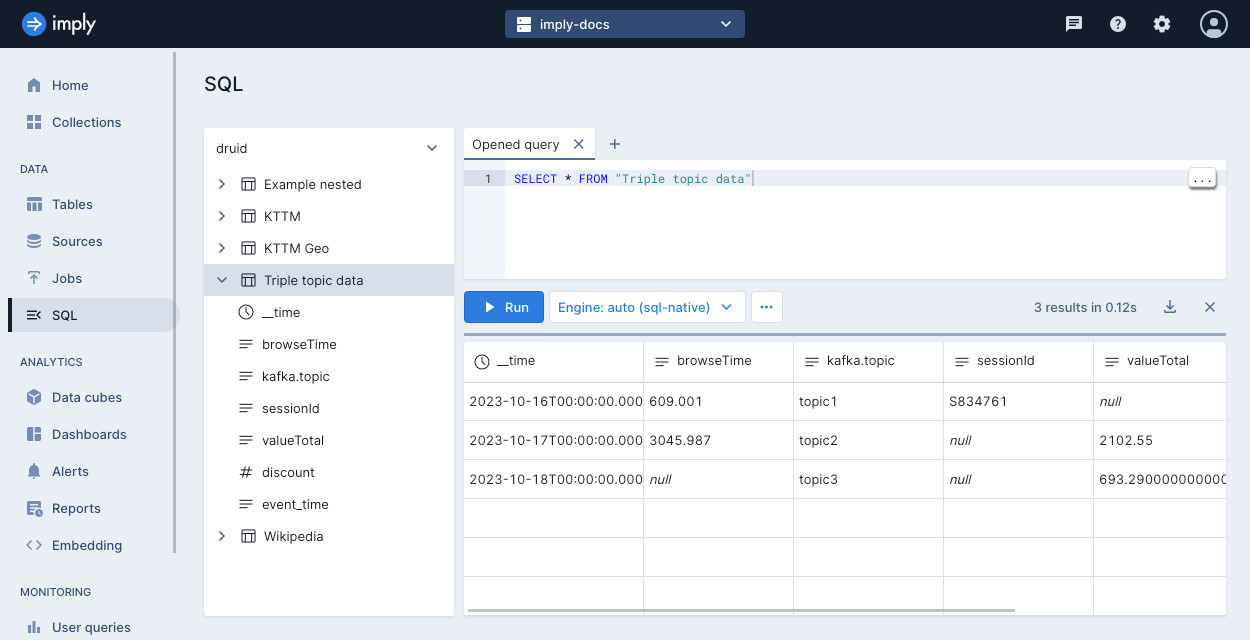
On the table view, select Query > SQL console to query the data in this example.
SELECT * FROM "Triple topic data"Notice the following details:
-
When you select a multi-topic connection as the source for an ingestion job, Polaris applies input expressions for all columns in all topics. Notice that the expression for
valueTotalis applied to rows that come from bothtopic2andtopic3. -
If a column exists in one topic but not the others, Polaris fills in null values from the topics that do not have the column. Rows produced by
topic1have a null value forvalueTotal, and the rows producedtopic3have null values forbrowseTime. -
If the data types of the input data do not match between different topics, Polaris assigns the widest data type that encompasses the data. Notice that the
browseTimecolumn contains the string data type sincetopic1sent this data as a float, andtopic2sent the data as a string.
-