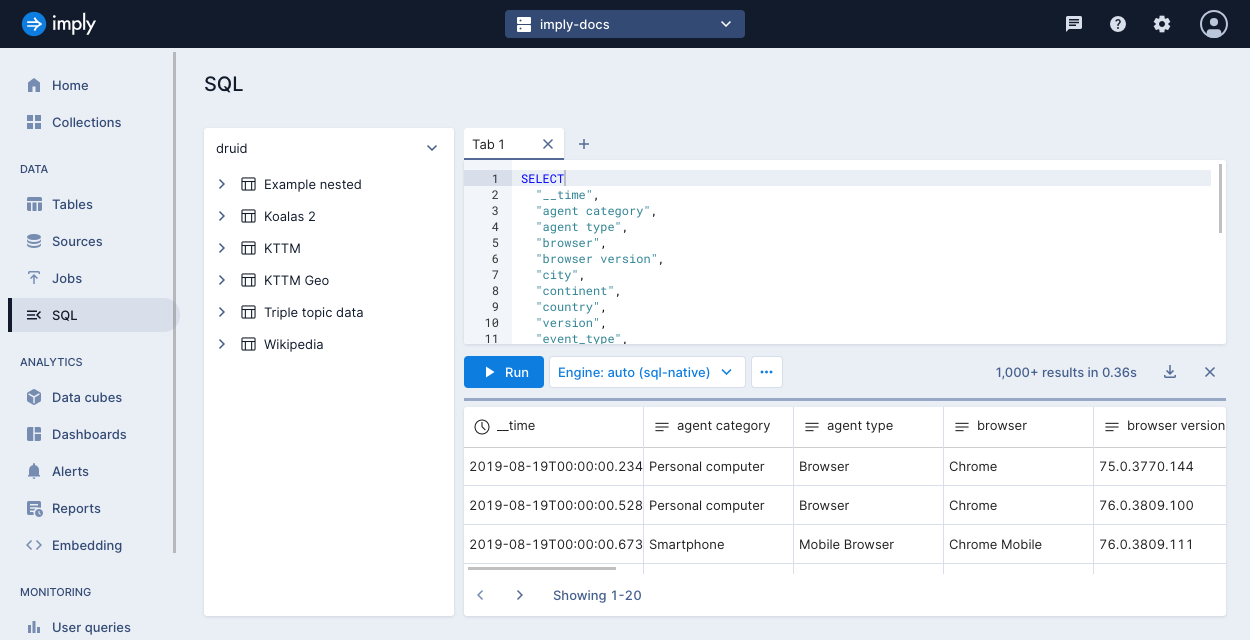
Query data
After you create a table and ingest data into Imply Polaris, you can use the SQL workbench to run queries against your data in the Polaris UI. You can also submit SQL queries using the Query API.
This topic explains how to query data in the SQL workbench. For information on how to use the Query API, see Query data by API.
Prerequisites
You need the AccessQueries permission to query data.
With the ManageIngestionJobs permission, you can also submit async queries that use INSERT or REPLACE.
For more information on permissions, see Permissions reference.
Use the SQL workbench
To access the SQL workbench:
-
Click SQL in the left navigation menu.
-
Click a table name in the left pane and select one of the shortcut queries from the pop-up menu.
-
Optionally, click the opened query tab to display the available tab actions.
-
Modify the query as required.
-
Select a query engine from the Engine drop-down.
-
Optionally, apply the tools from the ellipsis menu:
- Explain SQL query shows the native query plan returned by EXPLAIN PLAN for a SQL query.
- Prettify query formats your SQL code.
-
Click Run to execute the query.
-
Polaris displays the results in the bottom panel. Click the left and right arrows to page through the results. You can click the Copy query URL button to save a shareable URL to your clipboard. When you copy and paste the URL into a new browser tab, the query opens in a new SQL workbench tab. The URL opens the active query in a new browser tab.
You can also access the SQL workbench from the table details page—click Query in the top-right corner and select SQL console from the list of options.
Select a query engine
The query engine selector lets you choose an engine for Polaris to use when executing the query. By default, Polaris automatically selects the appropriate engine based on the query analysis that it performs in the background. The engines match up with the Query API endpoints as described below.
You can choose from the following options:
- Auto: Selects the endpoint automatically. If the query contains the INSERT statement or the REPLACE function, the engine defaults to SQL-async. Otherwise, it defaults to SQL-native.
- SQL-native: Sends a synchronous (sync) query to the
/query/sqlendpoint. This endpoint queries precached and real-time data and returns query results in the response. - Native: Sends an Apache® Druid native JSON query to the
/query/nativeendpoint. This endpoint returns results as an array of JSON objects. - SQL-dart: Sends a query to the
/query/sqlendpoint with the engine set to the Dart query engine. Dart offers better parallelism than the native engine. Use it for queries that include things like large joins, high-cardinality exactgroupByqueries, or high-cardinality count distinct queries. Dart supports several query context parameters. - SQL-async: Sends an asynchronous (async) query to the
/query/sql/statementsendpoint. This endpoint queries all data in deep storage. It doesn't return query results in the response. Instead, the response includes a query ID, which you can use to check the query status and retrieve the results.
When you select SQL-async, you can optionally configure the maximum number of tasks and choose a task assignment strategy. See SQL-async engine options for more information.
You can also use the query engine selector to specify the following query context parameters—changing these defaults may have performance implications. The available options depend on your selected engine.
- Edit context: Edit query context.
- Define parameters: Define dynamic parameters using question mark
?syntax. Polaris bounds parameters to?placeholders at execution time. - Timezone: Select a timezone type.
- Use cache: Use caching to improve query performance.
- Use approximate TopN: Use TopN approximation to improve query performance.
- Use approximate COUNT(DISTINCT): Use COUNT(DISTINCT) approximation to improve query performance.
- Limit inline results: Limit the number of results returned by the query. By default, the maximum number of results returned to the browser from a SELECT query is 1,000.
- Max parse exceptions: Set the maximum number of parse exceptions to ignore while executing the query. To ignore all parse exceptions, set the value to -1.
- Fail on empty insert: Determines how Polaris handles an ingest query that doesn't generate any output rows. If false, an INSERT query becomes a no-op query, and a REPLACE query deletes all data that matches the OVERWRITE clause. If true, the ingest query throws an exception.
- Finalize aggregations: Determines the type of aggregation to return. If true, Polaris finalizes the results of complex aggregations that directly appear in query results. If false, Polaris returns the aggregation's intermediate type rather than finalized type. This parameter is useful during ingestion, where it enables storing sketches directly in Polaris tables.
- Enable GroupBy multi-value unnesting: Controls the implicit unnesting behavior for GroupBy on multi-value columns. If true, Polaris expands the results into multiple rows before merging. If false, Polaris disables the behavior. In this mode, the engine returns an error instead of completing the query.
- Join algorithm: Algorithm to use for the JOIN operator. Use
broadcastfor broadcast hash join orsortMergefor sort-merge join. Affects all JOIN operations in the query. Join algorithm is a hint to execute the join in the specified manner. The actual joins in the query may proceed in a different way than specified. This is because the engine can decide to ignore the hint if it deduces that the specified algorithm can be detrimental to the performance of the join beforehand. See Joins for more information.
Dart query context parameters
In addition to the query context parameters provided in the UI, Polaris supports additional query context parameters for Dart. You can add following parameters through the Edit context option:
finalizeAggregationsincludeSegmentSourceremoveNullBytesmaxConccurrentStagesmaxNonLeafWorkerstargetPartitionsPerWorker
For information about these context parameters, see Query context parameters.
SQL-async engine options
The Max tasks drop-down appears when you select the SQL-async engine. You can use it to configure the maximum total number of tasks a query can launch. The lowest possible value of max tasks is two. Higher concurrency usually leads to faster execution time but consumes more compute resources. For example, the same query with a concurrency of two that takes 12 minutes to execute can take around six minutes to execute with a concurrency of four.
Note that depending on the task assignment strategy and files touched by the query, the query may not use the maximum available concurrency. We recommend that you experiment with and test your queries as performance can vary substantially between workloads.
Task assignment determines how many tasks a query can use. Possible values include:
- max: The query uses as many tasks as possible, up to the value of max tasks.
- auto: Polaris calculates file sizes using a weighted size approach, which accounts for the file format and any compression used. If Polaris can determine file sizes through directory listings, such as for local files or AWS S3, it optimizes the query to use as few tasks as possible. Polaris keeps each task under 512 MB or 10,000 files unless necessary to stay within the maximum total number of tasks. If Polaris can't determine file sizes through directory listings, as with HTTP sources, it defaults to the max task assignment strategy.
The following diagram illustrates how different task assignment strategies process 1 GB of data, assuming all other variables remain constant:

Interact with a results set
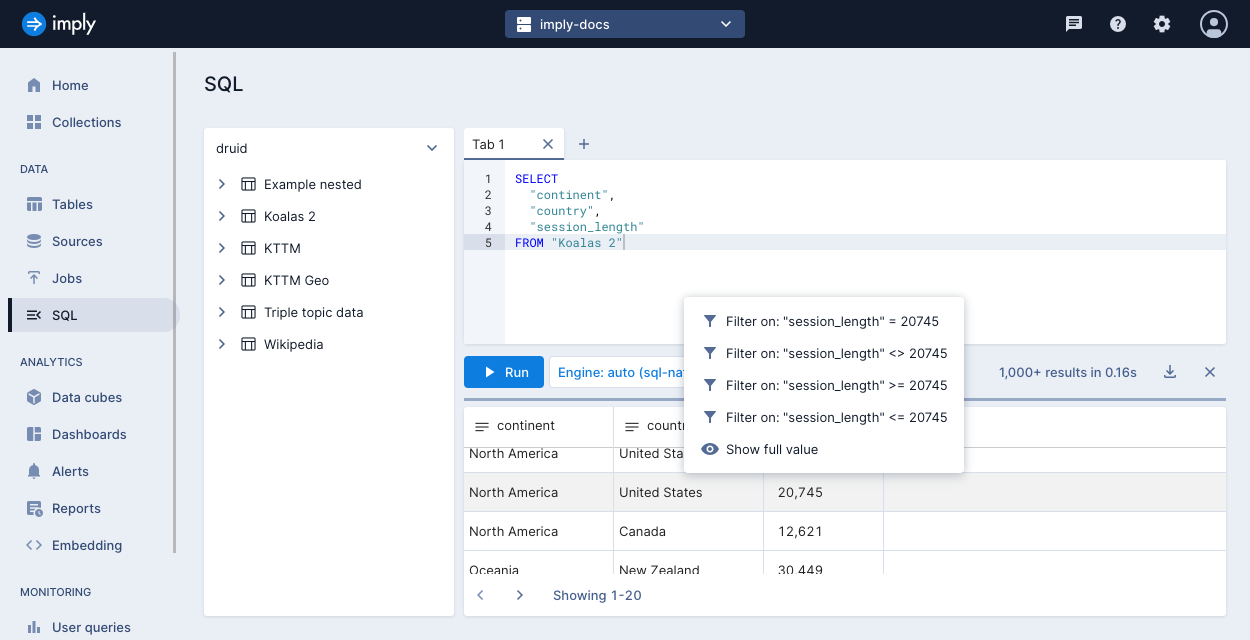
You can refine your query by interacting with the query results panel. Click any value in the results panel to view and select filter options.
For example, the following screenshot shows the results of this query:
SELECT "continent", "country", "session_length"
FROM "Koalas 2"
with filter options for value 20,745 in the session_length column.
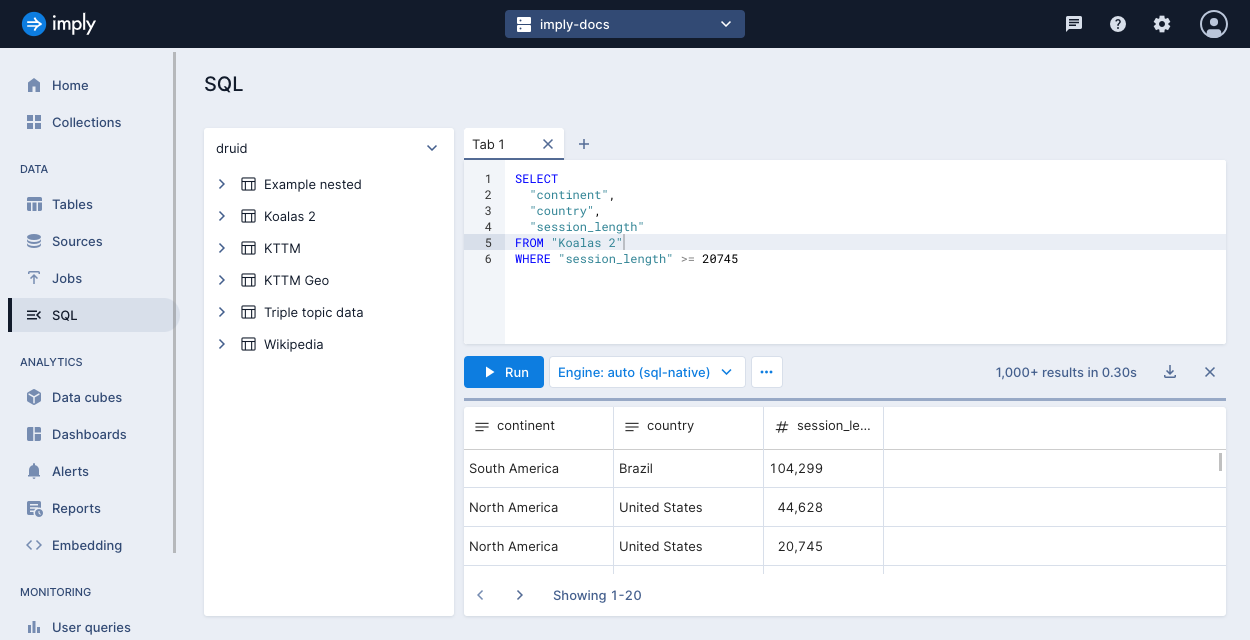
Selecting the filter session_length >= 20745 displays the results and adds the filter to the query:
Download query results
After your query completes, you can download query results as CSV, TSV, newline-delimited JSON, or SQL. Click the download button in the results panel to view and select download options.
Learn more
To learn more, see the following topics: