SQL
The SQL page in Pivot lets you query data sources from within Pivot using SQL:
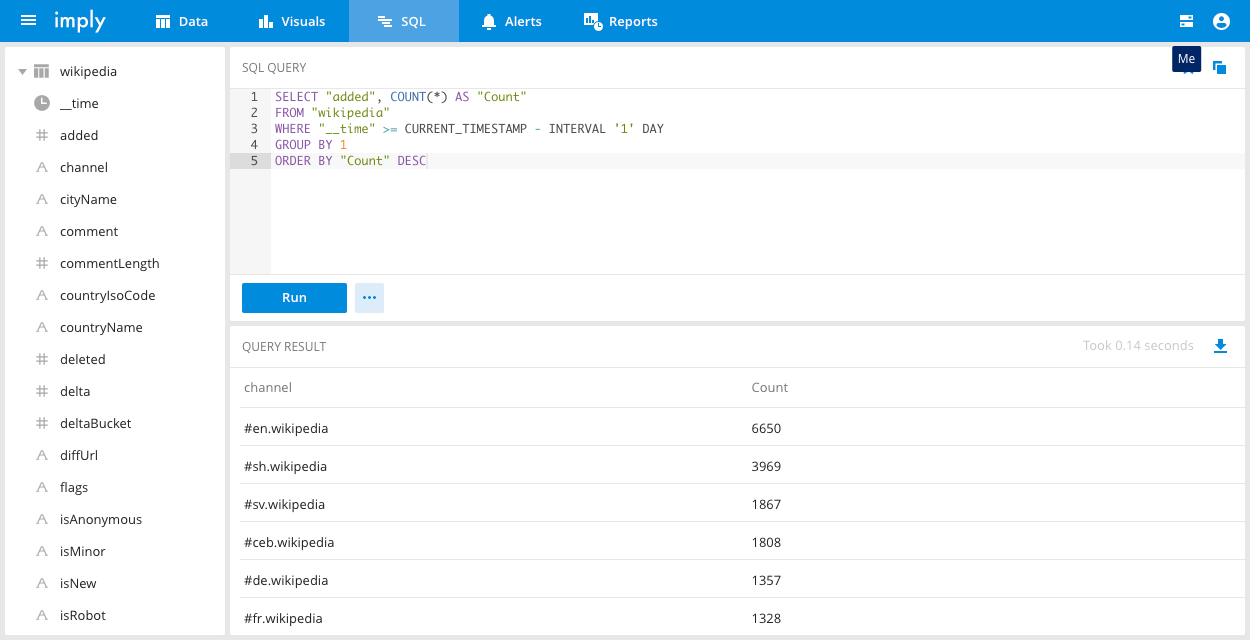
To run a query simply enter it into the SQL query box. You can make use of the auto complete feature and the schema on
the left to compose your query. Then click Run. The results will appear in the results pane. You can now iterate on
your query, share it, and download the results locally using the controls in the interface.
You can use the explain feature to view the query plan for a given SQL query. To do so, select Explain query from the ellipses menu ....
If user management is enabled in Pivot (the default in Imply Enterprise Hybrid), users need to have AccessSQL permissions to view or use the SQL interface.
Note that Pivot SQL underlies Pivot SQL data cubes. You can use SQL to create expressions for custom dimensions and measures. For more information, see Pivot SQL data cubes.
More information
For much more information on Druid SQL, including details on its features and syntax, see the Druid SQL documentation.