Access control
It is important to be able to restrict access to data. This section explains access control functionality built into Pivot.
The features discussed here assume that Pivot acts as a gatekeeper to the data store, that is, users can only query the data store via Pivot and never directly.
For Imply Enterprise (formerly Imply Private), the information presented in this section only applies if you are running Pivot in user enabled mode.
Data cube and dashboard access control
You can define access permissions for each data cube and dashboard from the Access tab. In the dashboard, open the Options panel to locate the Access tab.
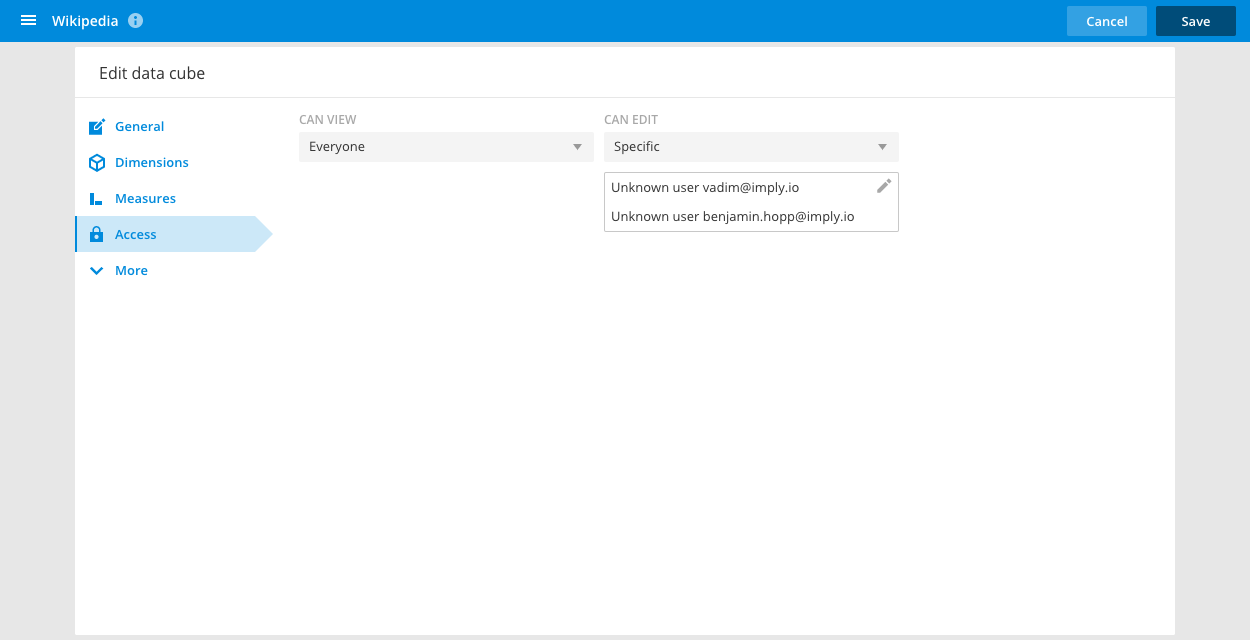
It is possible to restrict access to only specific people or specific roles. The edit access permissions of individual data cubes and dashboards only apply if the user has the ChangeDataCubes or ChangeDashboards permissions set. Similarly, a user possessing the AdministerDataCubes or AdministerDashboards permissions will be able to see and change all data cubes or dashboards respectively.
When you create a data cube or a dashboard, the default access controls are determined by the Default data cube view access configurations in the Settings tab.
Restricted edit mode for data cubes
In some cases, you may need to limit a user's ability to edit aspects of a data cube; for example, to allow a user to modify dimensions but not to change the title or description.
This can be done by configuring the data cube options
using the restrictedModeProperties key.
Row and column level restrictions
A data cube acts as a view (in the SQL sense) allowing you to specify a row level filter and restrict only certain columns for querying.
There are two use cases for restricting the data cube by rows or by columns:
- Refining the user experience with a data cube - maybe you want the user to focus on a meaningful subset of the data and tailor the dimensions and measures that a user sees accordingly.
- Letting certain users see only a specific slice of data for security reasons - maybe the user should not be able to see all the roles, or perhaps some columns contain sensitive data that certain users should not have access to.
For the second use case, make sure that the users you want to restrict do not have edit permissions to the data cube. Otherwise, they can edit the restrictions. By not giving users edit permissions, you can restrict their access to the data manager and the SQL IDE.
Any user who should be restricted from accessing all data for security reasons should only ever have the AccessVisualization and possibly QueryRawData permissions.
Row level restriction
It is possible to set a subset filter that would be silently applied to every query made through this data cube (this includes any dashboard tiles and Explain queries based on this data cube).
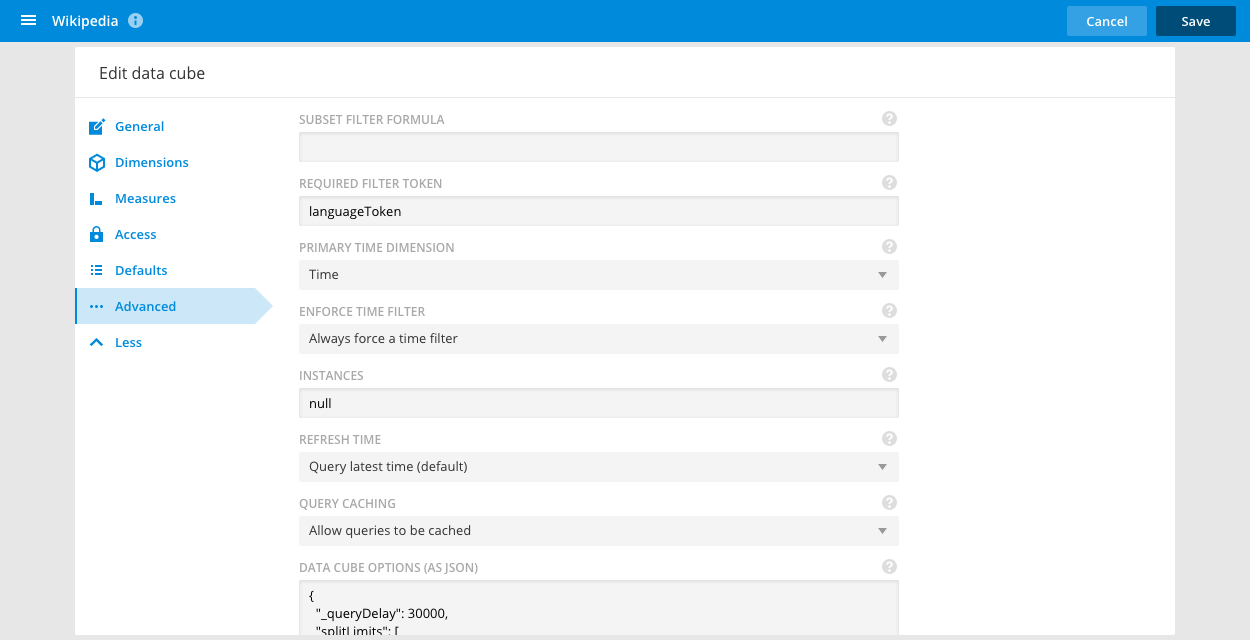
The subset filter is a Plywood expression and is editable in the Advanced tab of the data cube edit screen.
If a user does not have permissions to edit or create data cubes (or to access the SQL IDE, or query the data-store directly), then they will effectively be restricted to only seeing the data matched by the subset filter expression.
You can make this subset filter dynamic using filter tokens.
Column level restriction
You can only query the columns used in the dimensions and measures defined in the data cube. To restrict a user from querying certain columns in your data cube, do not define any dimensions or measures that use that column.
Filter tokens
You can define a filter token in Pivot that restricts user access to row-level data. You can apply several filter tokens to the same data so that different users have access to different subsets of data.
To create and apply a filter token:
- Create a user role and define a filter token for the role. Enter a name for the token and a filter formula with the appropriate syntax for the data cube type—Plywood or Pivot SQL. For example:
- Plywood filter formula:
$channel == '#fr.wikipedia' - Pivot SQL filter formula:
t.channel = '#fr.wikipedia'
- Plywood filter formula:
- Assign users to the role.
- Go to a data cube’s advanced options, and set the required filter token to the one you defined on the user role.
- View the data cube as a user assigned to the filtered role and confirm that the data is filtered as expected.
Filter token example
Let’s say you created a data cube from the Wikipedia datasource described in the Quickstart.
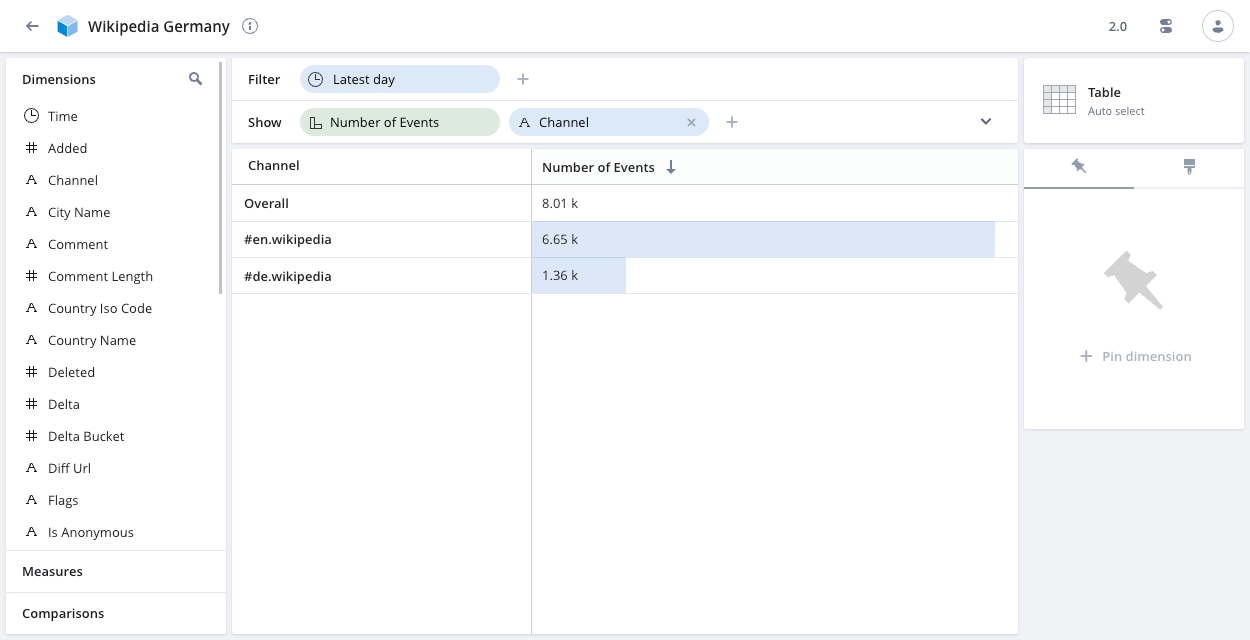
You have a group of data analysts in France and a group in Germany. You only want the analysts in each country to view data for their primary language Wikipedia channel plus the English language channel.
The following steps illustrate how to set up two filtered views of the same Pivot SQL data:
- Create a role named
Analysts Franceand assign it the following filter token:- Name:
france-filter-token - Filter formula:
t.channel IN ('#fr.wikipedia', '#en.wikipedia')
- Name:
- Create a role named
Analysts Germanyand assign it the following filter token:- Name:
germany-filter-token - Filter formula:
t.channel IN (‘#de.wikipedia', '#en.wikipedia')
- Name:
- Assign the analysts in France to the
Analysts Francerole and the analysts in Germany to theAnalysts Germanyrole. - Create a data cube on the Wikipedia data source named
Wikipedia France. In the advanced data cube options, set Required filter token:france-filter-token. - Create a data cube on the Wikipedia data source named
Wikipedia Germany. In the advanced data cube options, set Required filter token:germany-filter-token. - View the
Wikipedia Francedata cube as an analyst in France and theWikipedia Germanydata cube as an analyst in Germany, and confirm that the data is filtered as expected.
Filtered data cube for data analysts in France:
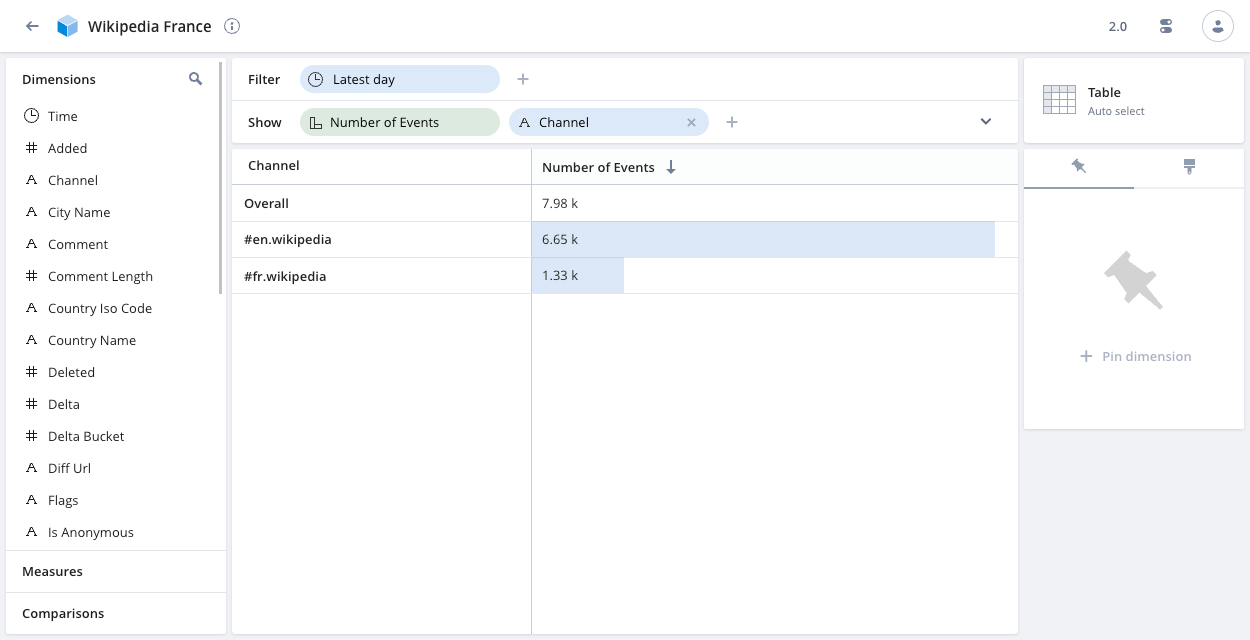
Filtered data cube for data analysts in Germany: