Download data
Pivot allows you to export aggregated data in a data cube view.
You may have multiple options available to download data, depending on whether you've enabled any optional download features. The options are outlined in the following sections:
- Standard download, available by default
- Async download (new engine, alpha feature)
- Async download (old engine, deprecated feature)
To download data from a data cube using any of these options, you must have the DownloadData permission applied to your user profile.
Standard download
In a data cube, click the Download data icon on the header bar to display the dialog:
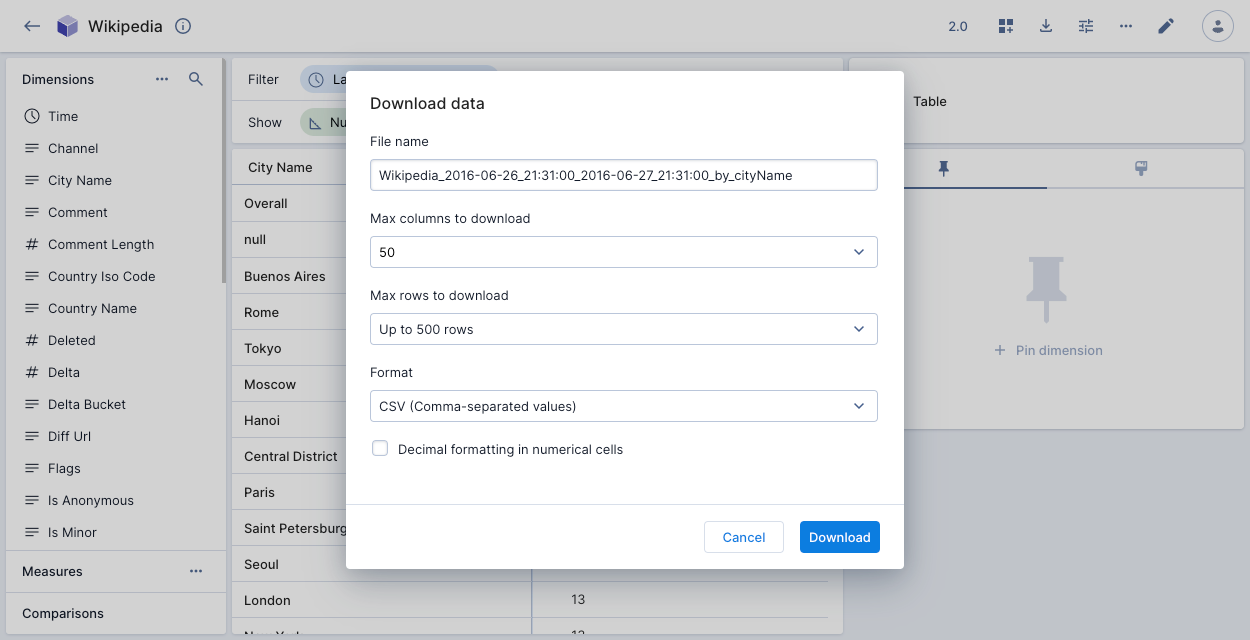
Complete the following fields, then click Download:
- File name: A name for the downloaded file.
- Max columns and Max rows to download. The available options depend on the data cube permissions and configuration. See Configure download limits for more information.
- Format: You can download the data as a CSV, TSV, JSON, or XLSX file.
- Decimal formatting in numerical cells: Apply decimal formatting to numerical cells in the download. You can configure the number of decimal places in the measure formatting. For example, if the default is
24433:- Decimal formatting:
24,433
- Decimal formatting:
Configure download limits
Pivot uses the following algorithms to download aggregated data:
- An iterative query method, which is fast and places light load on the cluster. The default maximum results set for this method is 5,000. To increase the limit, set
maxTotalQueriesForExportsin your Pivot configuration settings to a larger number. - A streaming Group By method, which is slower and uses more resources, but can work with large numbers of results (10,000+). A user must have the
DownloadLargeDatapermission for Pivot to make this method available.
To specify an absolute number of rows a user can export for a particular data cube, set the maxDownloadLimit property in the data cube options. By default there is no limit.
Classic data cubes
If you're a Hybrid customer, you can also download raw data from classic data cubes. To do this, select View raw data in the Options menu and click Download:
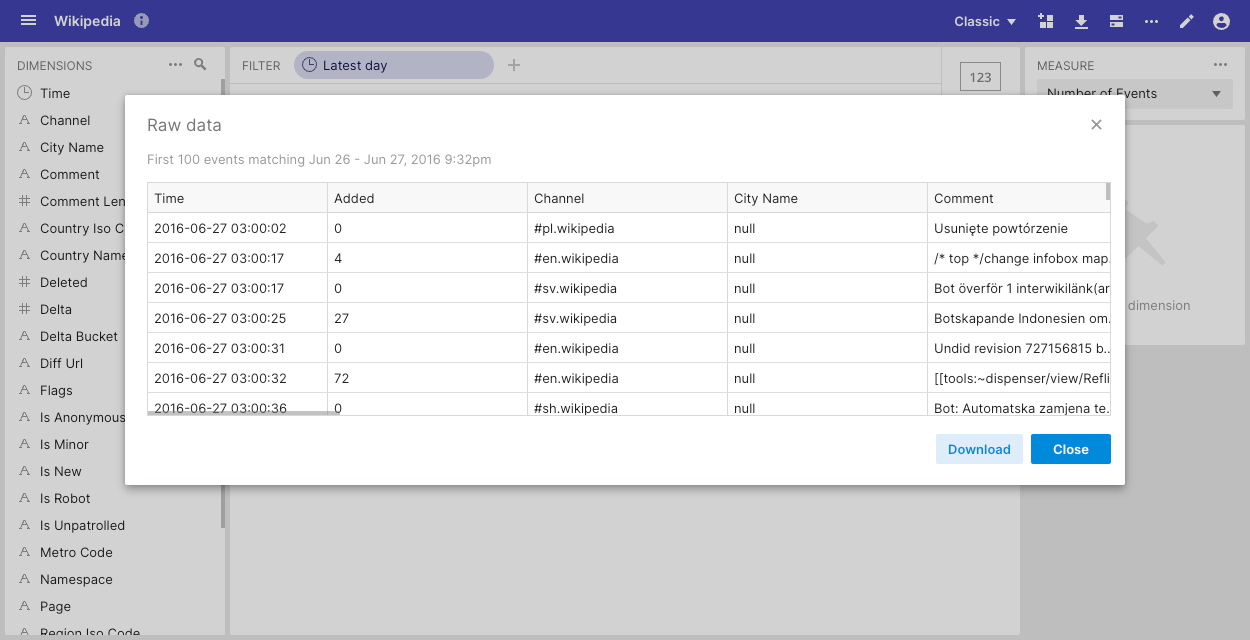
You can configure the maximum amount of exported raw data by setting rawDownloadLimit in the data cube options. By default the limit is 10,000.
Async download (alpha)
To enable this invite-only alpha feature, contact Imply support.
Download types feature flag
The alpha release async download feature uses a new engine to improve the reliability and completeness of async downloads. It also allows Pivot to retrieve data from deep storage.
The Download types (Alpha) feature flag that enables the feature also allows you to control the download options available to users in datacubes. The feature flag accepts a JSON array of values to enable download types and set their priority:
["standard","async"]sets standard download as the default experience, with async download (alpha) available as a secondary option.["async","standard"]sets async download (alpha) as the default experience, with standard download available as a secondary option.["standard"]sets standard download as the only download experience.["async"]sets async download (alpha) as the only download experience.
In the case of an invalid array, Pivot applies ["standard","async"]. An empty array turns off all downloads.
Use async download (alpha)
To use the async download (alpha) feature:
Click the Download data icon in a data cube. The default dialog allows you to use the Standard download.
To use the async download feature, click Use async download to display the following dialog:
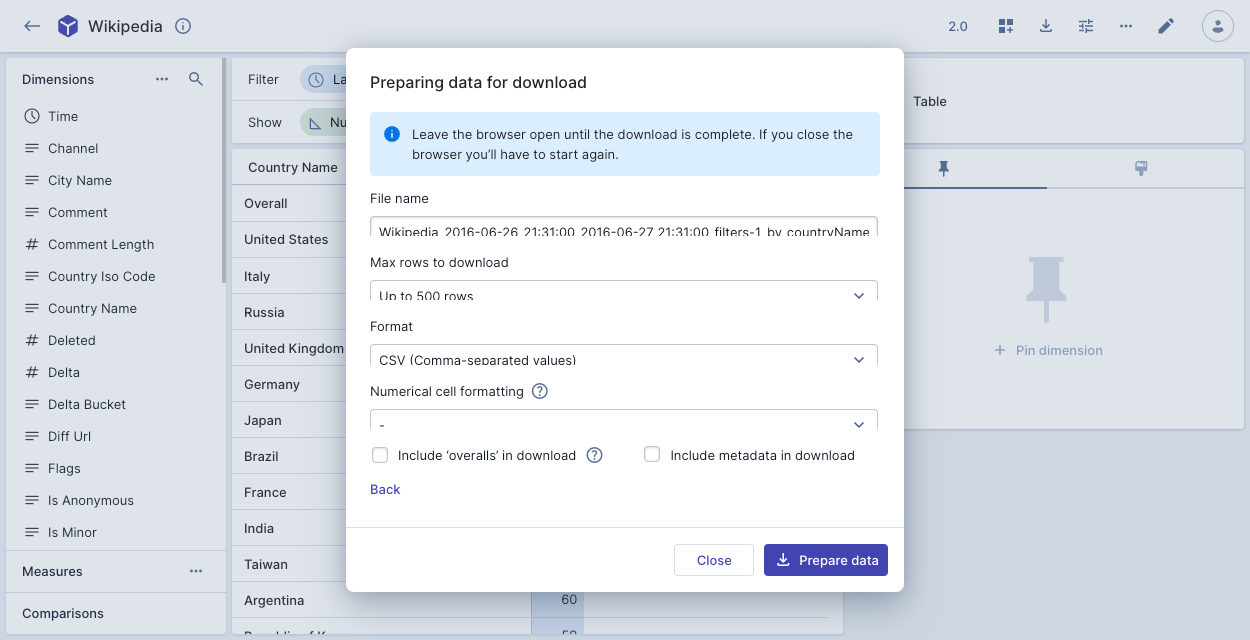
Complete the following fields, then click Prepare data:
- File name: A name for the downloaded file.
- Max rows to download: Maximum number of downloaded rows.
- Format: You can download the data as a CSV, TSV, or JSON file.
- Numerical cell formatting: Apply formatting to numerical cells in the download. You can configure the number of decimal places in the measure formatting. For example, if the default is
24433:- Decimal formatting:
24,433 - Abbreviations:
24.43k
- Decimal formatting:
- Include 'overalls' in download: Include a sum of all rows in the download.
- Include metadata in download: Include metadata such as the data cube name, table name, and filter details.
Once you click Prepare data, leave the browser open until the download is complete. You can continue using Pivot in the meantime.
Download old file version
If you prefer, you can click Download old file version to access the standard download option.
The standard download doesn't include formatting or metadata, and excludes any data saved to deep storage. It can be a quicker option for small data sets.
Data from deep storage
The alpha async download feature allows you to download data from deep storage.
Data cubes and visualizations don't display data that's only in deep storage, so you may notice a discrepancy between your displayed and downloaded data.
To restrict your download to recent data, apply a time limit or another limit to prevent Pivot from querying from deep storage.
Feature limitations
The following limitations apply to the alpha asynchronous downloads feature:
- XLSX file format isn't supported.
- A sort order applied to the data cube view doesn't apply to the downloaded data.
- If a data cube contains functions not supported by SQL-based ingestion, you can't download data from the data cube.
- Percent of parent measure transformations aren't supported. If your data cube contains a percent of parent measure transformation, the async download fails silently.
Imply requires sufficient capacity for all ingestion-related tasks, as well as the tasks it requires for each concurrent download. You must plan for the additional capacity required for downloads, to prevent high processing times for ingestion jobs. See Capacity planning for more information.
Hybrid customers can use a worker select strategy with an affinityConfig property to improve load distribution.
Async download (deprecated)
The async download feature enabled with the Async Downloads (Deprecated) feature flag is now deprecated. If you're using this feature, contact Imply support to discuss your options.
If you're using this feature, click the Download data icon in a data cube to display the dialog:
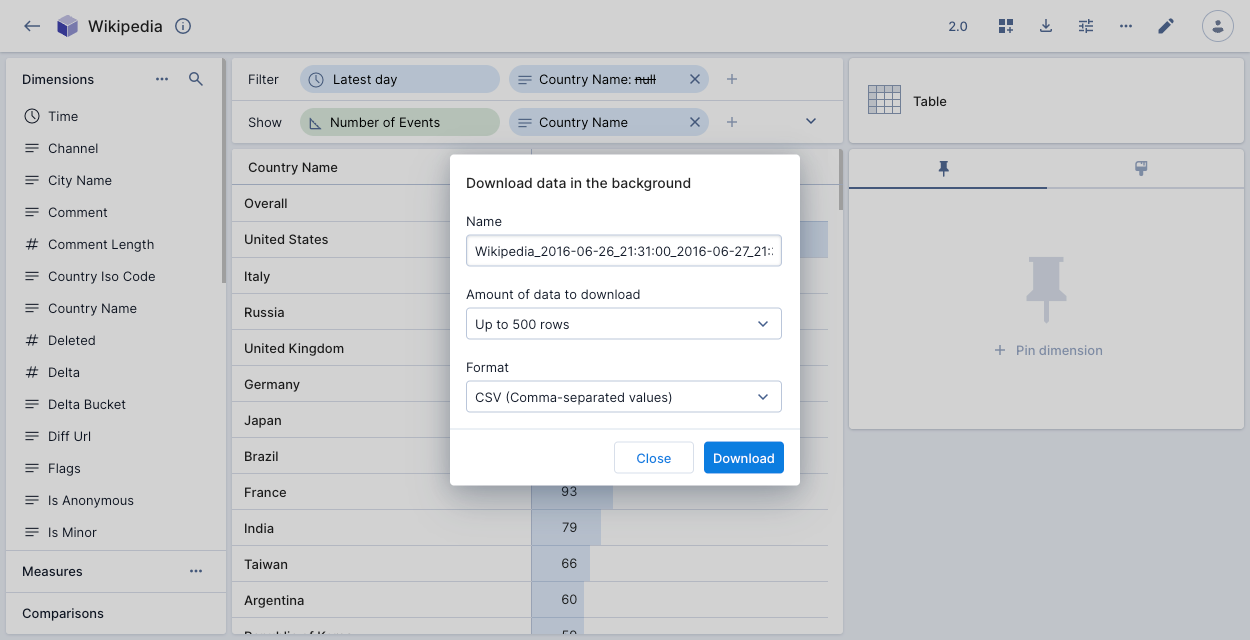
Complete the following fields, then click Download:
- File name: A name for the downloaded file.
- Amount of data to download: Select the number of rows to download.
- Format: You can download the data as a CSV or JSON file.
Feature limitations
The following limitations apply to the deprecated asynchronous downloads feature:
- You can only download data in CSV or JSON format.
- A sort order applied to the data cube view doesn't apply to the downloaded data.
- The download doesn't include measure transformations.
- You can't navigate to another browser tab or leave Pivot while your asynchronous download is in progress.
- Cells with
NULLvalues are blank. - If you download a single value, the header is
__VALUE__. - Personal Identifiable Information (PII) masking:
- In a standard download, an aggregate row named
Othersdisplays a count of masked rows. This isn't shown in async downloads. - There's no row enumeration appended to hidden rows.
- When
hideAggregatesis set to true in the PII mask properties and a row is masked, the value for an aggregate in that row is blank in the download.
- In a standard download, an aggregate row named
Using the deprecated async downloads feature requires careful tuning of certain Druid properties. Refer to Asynchronous SQL download (deprecated) for more information.