Data export
Pivot allows you to export the data in the currently selected view.
All data export actions require the user to have the DownloadData permission applied to their profile.
Exporting aggregated data
To export data in a data cube, click the Download data icon on the header bar to display the dialog:
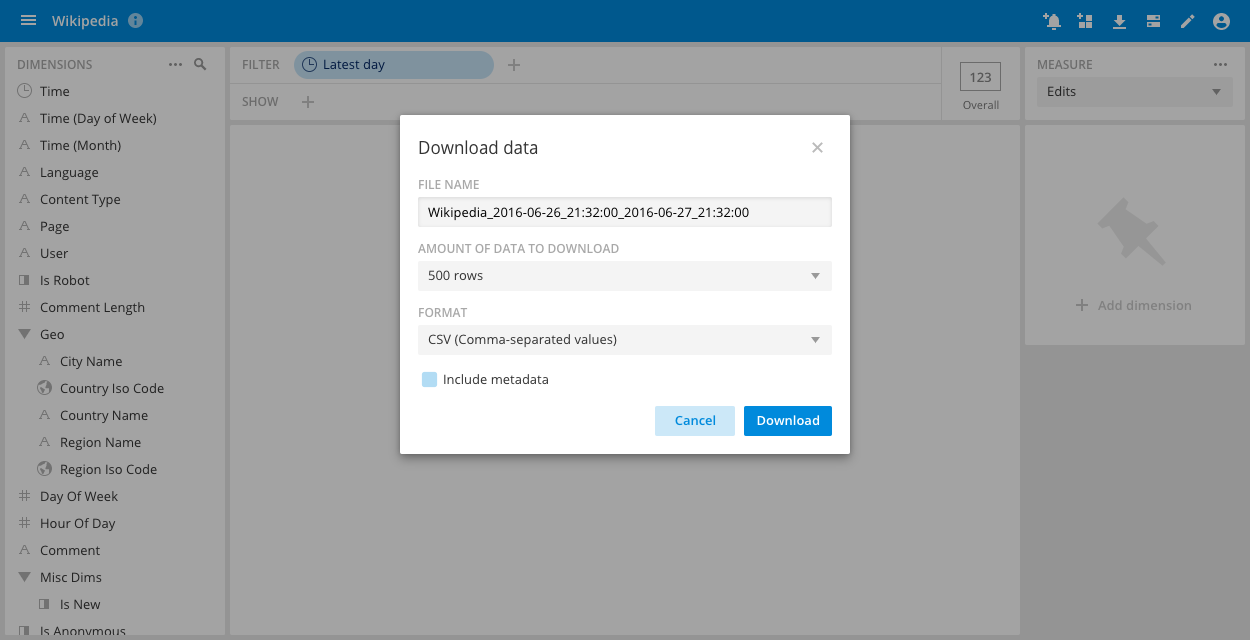
Select the number of rows to return. The available options depend on the data cube permissions and configuration. See Configuring download limits for more information.
You can export the aggregated data as a CSV, TSV, JSON, or XLSX (Excel) file. If you export data using async downloads, the available file types are CSV and JSON. See Async downloads for more information.
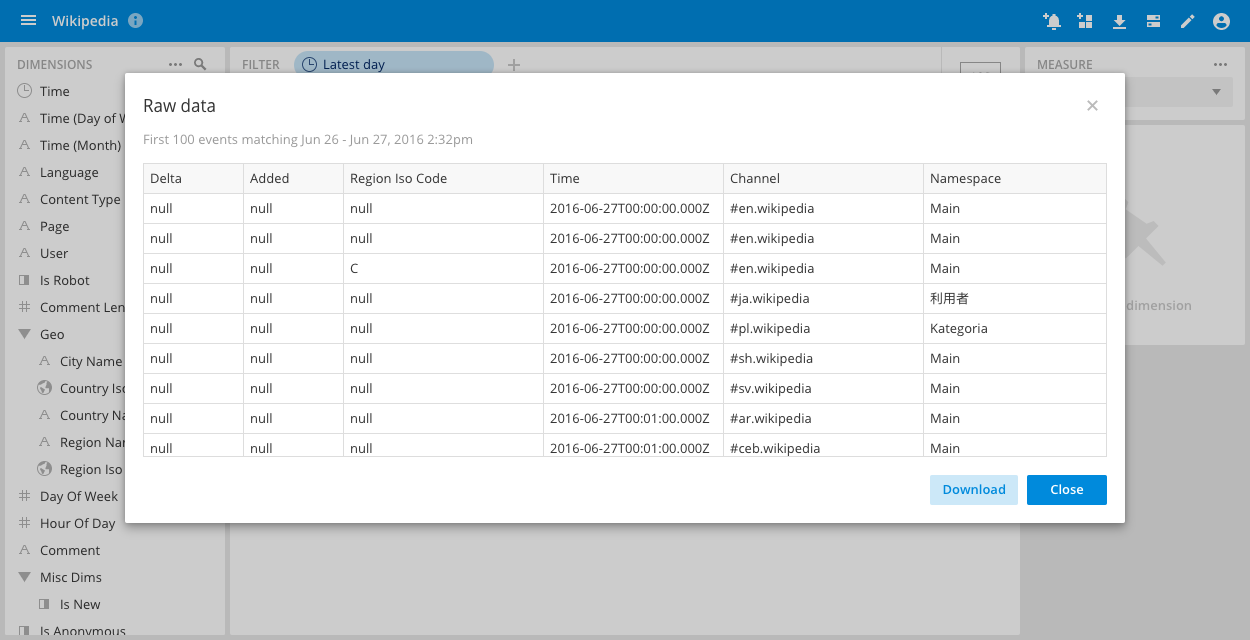
Exporting raw data
You can also export the raw data for the selected filter by selecting View raw data in the Options menu and clicking Download:
Configuring download limits
When running a multi-tenant application, it's important to configure the limits placed on downloads to balance the users need to export a lot of data and the stability of the cluster.
Configuring aggregated data download limits
Pivot uses the following algorithms to download aggregated data:
- An iterative query method, which is fast and places little load on the cluster. The default maximum results set for this method is 5,000. To increase the limit, set
maxTotalQueriesForExportsin your Pivot configuration settings to a larger number. - A streaming Group By method, which is slower and uses more resources, but can work with large numbers of results (10,000+). A user must have the
DownloadLargeDatapermission for Pivot to make this method available.
To specify an absolute number of rows a user can export for a particular data cube, set the maxDownloadLimit property in the data cube options (JSON). By default there is no limit.
Configuring raw data download limits
You can configure the amount of data that gets exported when the user downloads raw data from the raw data view by setting rawDownloadLimit in the data cube options (JSON), which defaults to 10,000.
Async downloads (deprecated)
Asynchronous download is deprecated.
Downloading large amounts of data in Pivot can take a lot of time and yield inconsistent results, with the possibility of browser timeouts or other errors interrupting the download. Additionally, with the traditional data download method, users couldn't use Pivot while the download was occurring.
With asynchronous (async) downloads, data downloading occurs in the background, allowing users to continue interacting with Pivot while the download completes, and with greater reliability for large downloads.
Enabling async downloads
A Pivot administrator must enable the async downloads feature flag in the Pivot advanced settings to make the feature available. When the feature is enabled, the title of the download dialog is Download in the background.
Using async downloads
To use asynchronous downloads:
Ensure that async downloads are enabled. See Enabling async downloads for details.
From a data cube, click the Download data icon on the header bar.
Enter the name of the file, the maximum amount of data to download, and select CSV or JSON file format. You can set the maximum download rows to avoid excessive downloads.
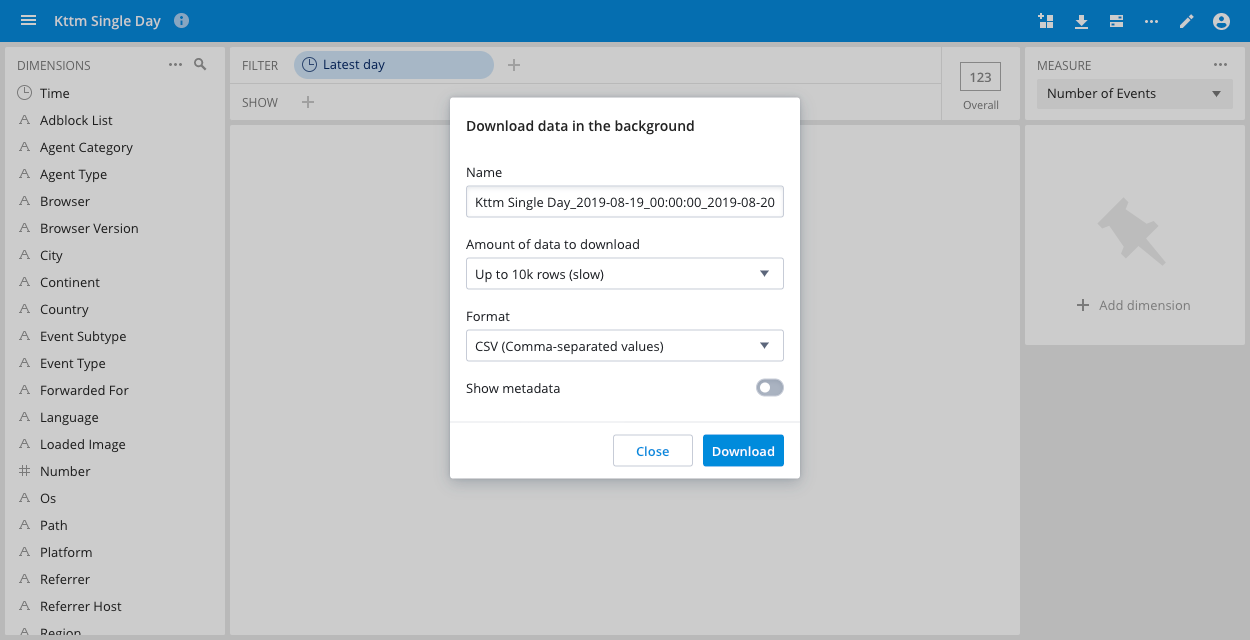
Click Download.
You can continue to use other Pivot features while you wait for your download to complete.
Asynchronous downloads notes
This section covers known limitations and explains the difference between traditional and asynchronous downloads.
Limitations of asynchronous downloads
The following limitations apply to asynchronous downloads:
- You can only download data in CSV or JSON format.
- You can't download measure transformations.
- You can't navigate to another browser tab or leave Pivot while your asynchronous download is in progress.
- Use of async downloads requires careful tuning of certain Druid properties and is subject to limitations with other Druid properties. We strongly advise that you refer to Async SQL downloads in the Druid documentation before you enable this feature.
Differences between traditional and asynchronous downloads
- Async downloads may generate documents in which the data ordering doesn't necessarily follow the source, whereas traditional downloads usually do.
- Cells with
NULLvalue are blank in async downloads. - If downloading a single value, the header in async downloads is
__VALUE__. - Personal identifiable information (PII) masking.
- In traditional downloads, an aggregate row called "Others" is added to the download for the count of masked rows. This isn't shown in async downloads.
- There's no row enumeration appended to hidden rows.
- When
hideAggregatesis true and a row is masked, the value for an aggregate in that row isNULL(blank in the download), rather than the underlying value.