Compaction
Optimizing segments
A Druid datasource is partitioned into segments that are served by Historical processes for query processing. It's very important for segment sizes to be optimized for both disk utilization and query processing efficiency.
Druid supports compaction, in which small segments may be merged and large ones may be split to optimize their size. Merging small data segments into larger ones is especially important for data ingested from streams, since the ingestion rate may vary over time, and some data may even arrive late, resulting in highly variable segment sizes.
You can schedule automatic compaction as needed. Auto compaction works by analyzing each time chunk for sub-optimally-sized segments, and kicking off tasks to merge them into optimally sized segments. See Coordinator's automatic segment compaction for details.
To achieve faster and more scalable compaction performance, auto compaction can run parallel tasks to compact a particular time chunk. To enable parallel compaction, set maxNumConcurrentSubTasks to something higher than 1 in the tuningConfig field. However, note that setting maxNumConcurrentSubTasks to a value that is too large can disrupt performance of other ingestion jobs. See TuningConfig for details.
You can configure compaction from the Edit compaction configuration dialog in the Druid console, which you can access for each datasource from its action menu.
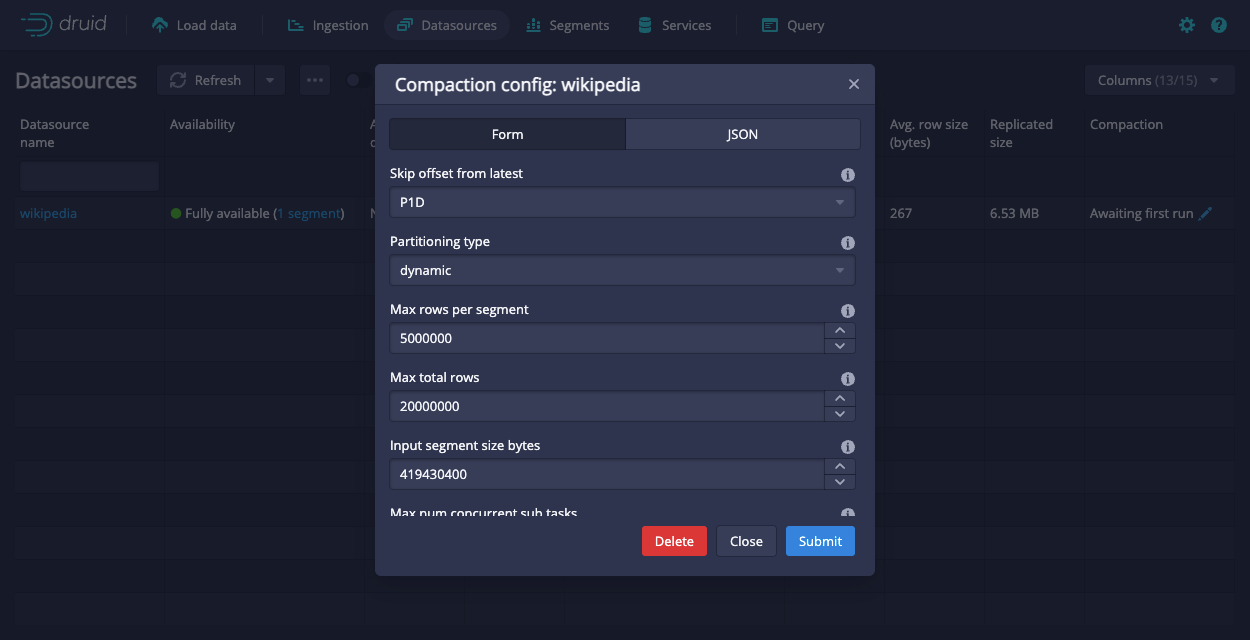
Use JSON format when entering values into the tuning config field, for example, "maxNumConcurrentSubTasks": 2.
The following tables describe the settings and list their corresponding Druid configuration properties. See Coordinator's dynamic configuration for more details.
Mandatory settings
| Name | Druid configuration name | Description |
|---|---|---|
| Input segment size bytes | inputSegmentSizeBytes | Maximum number of total segment bytes processed per compaction task. If maxNumConcurrentSubTasks is set to 1, each compaction task runs within a single thread and setting this value too far above 1–2 GB will result in compaction tasks taking an excessive amount of time. If maxNumConcurrentSubTasks is set to a value greater than 1 in the tuningConfig, a compaction task can employ multiple subtasks for compacting the same time chunk in parallel and this value can be essentially unlimited, but should be set to any value larger than the total segment size of any time chunks. To avoid using an excessive amount of cluster resources, please set maxNumConcurrentSubTasks carefully. |
| Skip offset from latest | skipOffsetFromLatest | The offset for searching for segments to be compacted. Strongly recommended to set for realtime datasources. Please check the below note for details. |
Automatic compaction cannot run for time chunks that are currently receiving data; if new data comes in while compaction is in progress, compaction is canceled. To avoid this conflict, you can use the “skip offset from latest” option to avoid recent time chunks where late data might still be coming in.
Advanced settings
| Name | Druid configuration name | Description |
|---|---|---|
| Max rows per segment | maxRowsPerSegment | Maximum number of rows per segment after compaction. |
| Task context | taskContext | Task context for compaction tasks. |
| Task priority | taskPriority | Priority of compaction tasks. |
| Tuning config | tuningConfig | Tuning config for compaction tasks. Note that compaction tasks share the same tuning config with Druid's native parallel task. See TuningConfig for details. |