Developer and API guide
The Imply Polaris API provides programmatic access to working with resources such as tables, files, and ingestion jobs in Polaris.
You can also use the Python SDK for Polaris. The SDK is an abstraction layer on top of the Polaris API that allows you to manage your Polaris resources using Python. For package details and installation, see Polaris SDK.
To use the Polaris API, you must first authenticate to verify your identity. Polaris supports API key and OAuth authentication methods. For more information on authenticating REST API requests, see Authentication overview.
The following diagram presents a high-level approach to working with the Polaris API, showcasing example workflows for some of the ingestion sources that Polaris supports. Navigate to the associated developer guide to learn more about any step.

Create an API key
We recommend using API keys to authenticate to the Polaris API. To learn more about the benefits of API key authentication see Authentication overview. For instructions on how to create an API key see Create API keys.
Identify your API endpoint
Your API endpoint is the location where the API sends and receives requests. The API endpoint for Polaris follows the format: https://ORG_NAME.REGION.CLOUD_PROVIDER.api.imply.io/v1/projects/PROJECT_ID. To find your API endpoint:
-
Select
Sourcesin the left navigation menu. -
Near the top right corner of the page, select Create source > Upload via API to display instructions to upload a file using the API.
-
Your API endpoint is the URL on the first line of the curl command. You can copy and paste it to use where needed.
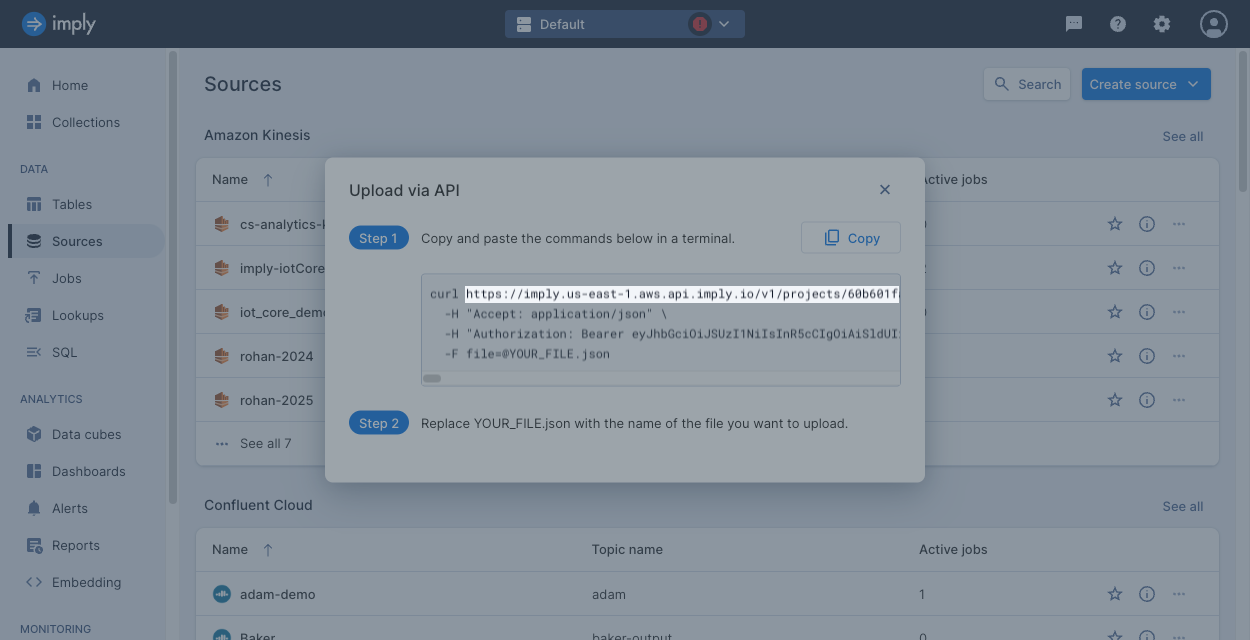
By referencing the endpoint format you can find the organization name, region, cloud provider, and project ID embedded in the URL. For more information on base URL path parameters, refer to the API reference.
Prepare your table (optional)
Before you ingest data into Polaris, you can create a table and define its schema. This step is optional—you do not have to create a table before starting an ingestion job. For ease of use, Polaris can automatically create a table with the appropriate table type and schema mode. If you prefer stricter data governance and schema design, create the table yourself. When you create the table manually, you can determine the table type, schema mode, partitioning, and rollup, among other characteristics. You can make some updates to a table after it's created; however, its name and type cannot be changed.
A table schema is only required for tables with strict schema enforcement. If you want to enforce strict schema conformity on your data, use a strict table. If you want to allow for a changing or flexible schema, use a flexible table. Polaris creates tables in flexible schema mode by default.
For Polaris to create your table, set createTableIfNotExists to true in the ingestion job spec.
Polaris automatically determines the table attributes from the job spec.
For details, see Automatically created tables.
Connect to a source of data
Specify the source of your data. For most sources, you need to create a connection to access the data.
- For batch ingestion from files, upload files to a staging area.
- For streaming ingestion or batch ingestion from Amazon S3, create a connection to define the source of data. For example, push streaming, Confluent Cloud, Amazon S3, Apache Kafka®.
Ingesting from an existing Polaris table does not require additional information.
For more information on ingestion sources, see Ingestion sources overview.
Ingest data
Create an ingestion job to define the source data, destination table, and any transformations to apply to the data before ingestion. You can also use SQL as opposed to the JSON job spec to describe the ingestion job.
Streaming ingestion jobs have additional options you can set to control schema auto-discovery or the position to read from the topic or stream.
For a push streaming connection, you also need to push events to the connection.
Analyze data
Use the Polaris APIs to create data cubes, dashboards, embedding links, alerts, and reports. See Guide for analyzing data for details.
Query the data using the SQL workbench in the UI or submit SQL queries using the API.
You can also integrate external applications with Polaris:
- Connect over JDBC: Connect a JDBC driver to Polaris.
- Link to BI tools: Access Polaris data from business intelligence tools such as Tableau, Looker, Apache Superset, and Grafana.
Learn more
For more information on the Polaris API, see API reference.