Extensions
Apache Druid® implements an extension system that allows for adding functionality at runtime. Extensions are commonly used to add support for deep storage (HDFS and S3), metadata stores (MySQL and PostgreSQL), new aggregators, and new input formats.
Imply bundles many commonly used Druid extensions, including core extensions, out of the box. Production clusters generally use at least two extensions: one for deep storage and one for a metadata store.
Not all Druid core extensions are intended for use or packaged with Imply. For instance, the Apache Druid pac4j extension is not supported.
Imply bundled extensions
Imply's distribution of Apache Druid loads a certain set of Druid extensions by default. Additionally, some extensions are loaded dynamically based on the specific conditions and selections made in the UI.
Default extensions
The following table lists extensions included with Imply's distribution of Apache Druid (version 4.0.0 or higher). The link on each extension name takes you to the documentation for that extension.
| Name | Description |
|---|---|
| druid-datasketches | Support for approximate counts and set operations with DataSketches. |
| druid-histogram | Approximate histograms and quantiles aggregator. This extension is deprecated. Use the DataSketches quantiles aggregator from the druid-datasketches extension instead. |
| druid-kafka-indexing-service | Supervised exactly-once Kafka ingestion for the indexing service. |
| druid-kinesis-indexing-service | Supervised exactly-once Kinesis ingestion for the indexing service. |
| druid-lookups-cached-global | A module for lookups providing a jvm-global eager caching for lookups. It provides JDBC and URI implementations for fetching lookup data. |
Conditional extensions
The following table lists conditional extensions that are loaded dynamically based on the cluster’s configuration. Imply's distribution of Apache Druid (version 4.0.0 or higher) automatically loads these extensions when the relevant conditions are met. When available, the link on each extension name takes you to the documentation for that extension.
| Name | Description | Condition |
|---|---|---|
| druid-basic-security | Support for Basic HTTP authentication and role-based access control. | Customer enabled authentication for their cluster. |
| druid-hdfs-storage | HDFS deep storage. | Customer uses HDFS for deep storage. |
| druid-s3-extensions | A module for interfacing with data in AWS S3 and using S3 as deep storage. | Customer uses AWS S3 for deep storage. |
| clarity-emitter | A module for pushing metrics to Imply's Clarity service. | Customer configured a Clarity account. |
| imply-druid-security | Druid authentication and authorization extension for Imply Cloud. For Imply internal use only. | Customer enabled authentication for their cluster. |
| mysql-metadata-storage | MySQL metadata store. | Customer uses a MySQL-type metadata store. |
| postgresql-metadata-storage | Postgresql metadata store. | Customer uses a Postgresql-type metadata store. |
| simple-client-sslcontext | Simple SSLContext provider module to be used by Druid's internal HttpClient when talking to other Druid processes over HTTPS. | Customer enabled TLS for their cluster. |
Optional extensions
The following table lists optional extensions packaged with Imply's distribution of Apache Druid (version 4.0.0 or higher). You can add these extensions to a cluster node to enhance functionality. When available, the link on each extension name takes you to the documentation for that extension.
| Name | Description |
|---|---|
| druid-avro-extensions | Support for data in Apache Avro data format. |
| druid-azure-extensions | Microsoft Azure deep storage. |
| druid-bloom-filter | Support for providing Bloom filters in Druid queries. |
| druid-google-extensions | Google Cloud Storage deep storage. |
| druid-kafka-extraction-namespace | Kafka-based namespaced lookup. Requires namespace lookup extension. |
| druid-kerberos | Kerberos authentication for druid processes. |
| druid-orc-extensions | Support for data in Apache Orc data format. |
| druid-parquet-extensions | Support for data in Apache Parquet data format. Requires druid-avro-extensions to be loaded. |
| druid-protobuf-extensions | Support for data in Protobuf data format. |
| druid-stats | Statistics related module including variance and standard deviation. |
| imply-timeseries | A module to enable time series functions. |
| imply-utility-belt | A module to parse the CloudWatch log container format. For Imply internal use only. |
| indexed-table-loader | Joinable indexed tables (alpha). |
druid-google-extensionsanddruid-azure-extensionsare loaded dynamically when a customer uses Google Cloud Storage or Azure Storage respectively.
Loading bundled extensions with Imply Manager
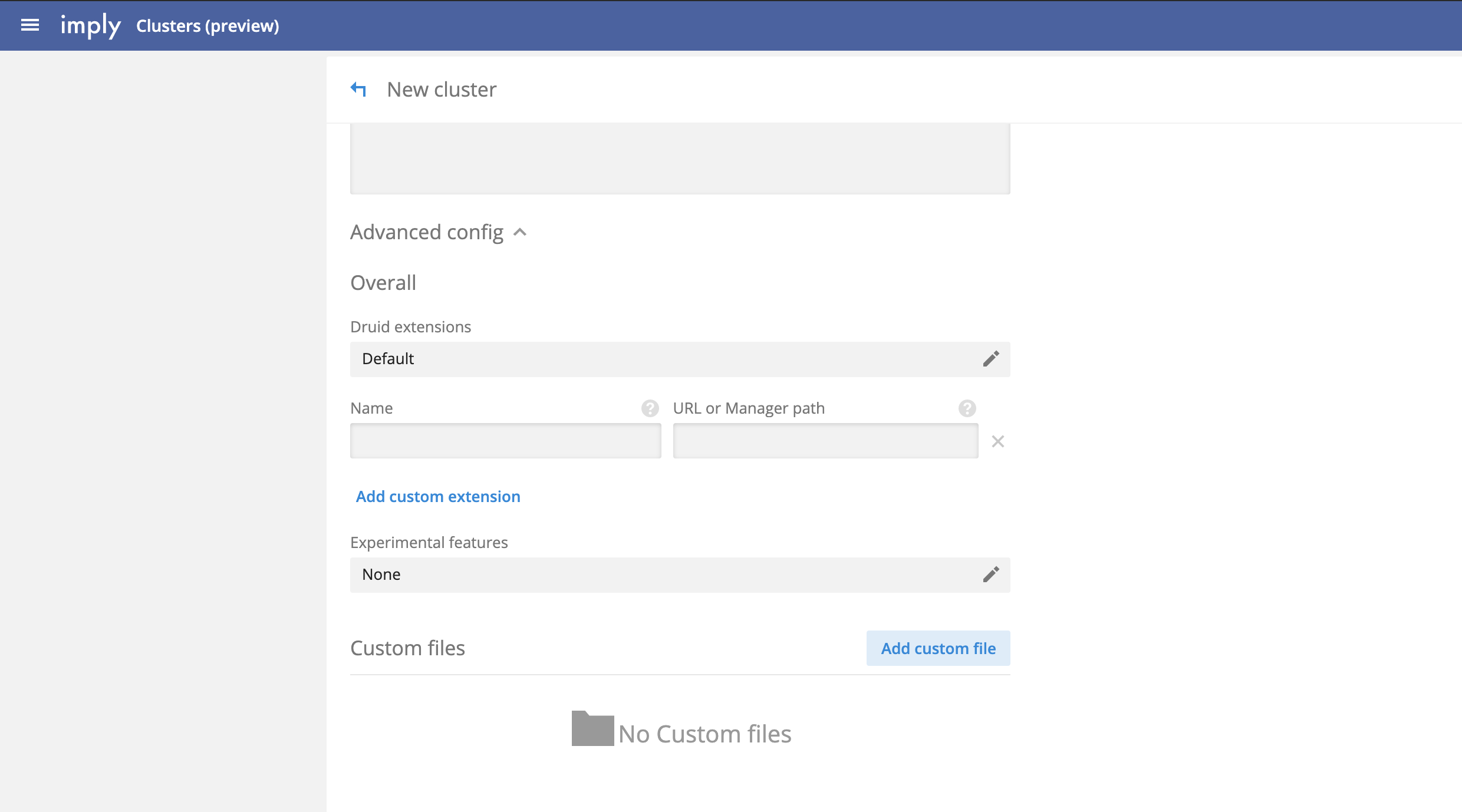
You can manage bundled Druid extensions in Imply Manager. To view bundled extensions, open the cluster's Setup tab and go to Advanced config > Druid extensions.
Extensions loaded by default are grouped together under the Default option. You do not need to take any additional action to add them to your cluster.
To enable optional extensions, click the edit icon next to Druid extensions. This opens a pop-up window with optional extensions packaged with Imply.
Loading bundled extensions manually
If Imply's distribution of Apache Druid does not include Imply Manager, you can load bundled extensions by adding their names to the druid.extensions.loadList parameter of the common.runtime.properties file. For example, to load the postgresql-metadata-storage and druid-hdfs-storage extensions, use the following configuration:
druid.extensions.loadList=["postgresql-metadata-storage", "druid-hdfs-storage"]
For more information on setting Druid configurations, see Configuration reference.
Druid core extensions
Core extensions are maintained by Druid committers. Some are in preview status and some are fully production-tested Druid components. For a complete list of core extensions, see Druid core extensions.
Druid community and third-party extensions
Imply does not provide support for community and third-party extensions.
You can install community and third-party extensions that are not bundled with Imply's distribution of Apache Druid.
Community extensions are contributed by Druid community members. These extensions are not packaged with the default Druid tarball and are not maintained by Druid committers. For a list of available community extensions, see Druid community extensions.
Loading community extensions for Imply Enterprise
You can download community extensions using Druid's pull-deps tool. To do so, specify a -c extension coordinate to pull down, followed by a Maven coordinate: org.apache.druid.extensions.contrib:{EXTENSION_NAME}:{OSS_DRUID_VERSION}.
The version you provide should match the community Druid version that Imply's distribution of Apache Druid is based on. Since Imply STS releases are monthly, find the version of Druid that was released most closely to your Imply version. For example, to install
druid-time-min-max, run the following command:
java \
-cp "dist/druid/lib/*" \
-Ddruid.extensions.directory="dist/druid/extensions" \
-Ddruid.extensions.hadoopDependenciesDir="dist/druid/hadoop-dependencies" \
org.apache.druid.cli.Main tools pull-deps \
--no-default-hadoop \
-c "org.apache.druid.extensions.contrib:druid-time-min-max:{{OSS_DRUID_VERSION}}"
In common.runtime.properties, add druid-time-min-max to druid.extensions.loadList to instruct Druid to load the extension.
Loading third-party extensions for Imply Enterprise
To load a third-party extension into Imply Enterprise using Imply Manager, make the extension file available to Imply Manager from a filesystem location or by a URL. After making the extension file available, click Add custom extension and provide the extension name along with the URL or path to the extension file using the manager:///<path-to-extension> addressing scheme. For more information on pushing custom user files to Imply Manager, see Add custom user files.
To install a third-party extension manually, download the extension and then install it into your dist/druid/extensions/ directory. You can download the extension from its distributor's directly or, if it is available from Maven, use the included pull-deps tool. To use pull-deps, specify the full Maven coordinate of the extension in the form of groupId:artifactId:version.