Kafka ingestion tutorial
The Kafka indexing service enables you to ingest data into Imply from Apache Kafka. This service offers exactly-once ingestion guarantees as well as the ability to ingest historical data.
You can load data from Kafka in the Druid Console using the Apache Kafka data loader:
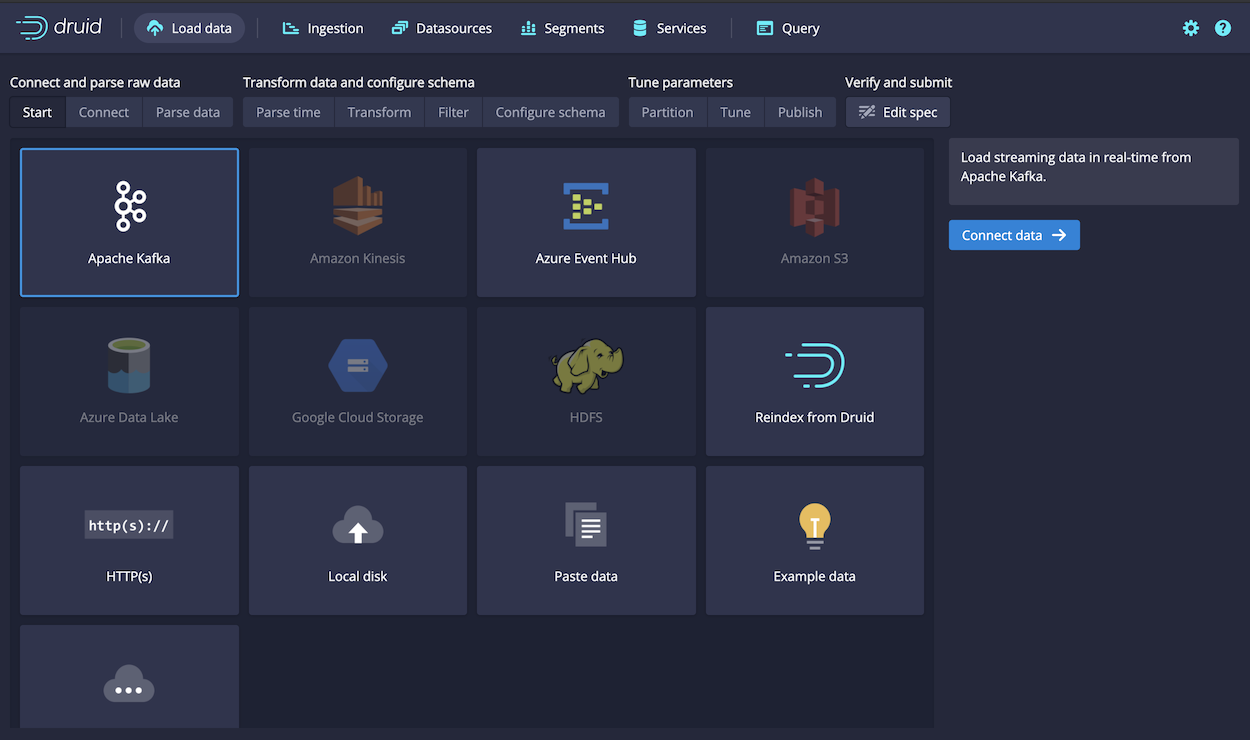
This tutorial guides you through the steps to:
- Set up an instance of Kafka and create a sample topic called
wikipedia. - Configure the Druid Kafka indexing service to load data from the Kafka event stream.
- Load data into the Kafka
wikipediatopic. - Create a data cube in Imply Pivot.
Before starting
Before you start the steps in this tutorial, ensure that you have access to a running instance of Imply. If you don't, see the Quickstart for information on getting started.
The Druid Kafka indexing service requires access to read from an Apache Kafka topic. If you are running Imply Hybrid (formerly Imply Cloud), consider installing Kafka in the same VPC as your Druid cluster. For more information, see Imply Hybrid Security.
Download and start Kafka
-
In a terminal window, download Kafka as follows:
curl -O https://archive.apache.org/dist/kafka/2.5.1/kafka_2.13-2.5.1.tgz
tar -xzf kafka_2.13-2.5.1.tgz
cd kafka_2.13-2.5.1This directory is referred to as the Kafka home for the rest of this tutorial.
-
If you're already running Kafka on the machine you're using for this tutorial, delete or rename the
kafka-logsdirectory in/tmp.Imply and Kafka both rely on Apache ZooKeeper to coordinate and manage services. Because Imply is already running, Kafka attaches to the Imply ZooKeeper instance when it starts up.
In a production environment where you're running Imply and Kafka on different machines, start the Kafka ZooKeeper before you start the Kafka broker. -
In the Kafka root directory, run this command to start a Kafka broker:
./bin/kafka-server-start.sh config/server.properties -
In a new terminal window, navigate to the Kafka root directory and run the following command to create a Kafka topic called
wikipedia:./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic wikipediaKafka returns a message when it successfully adds the topic:
Created topic wikipedia.
Enable Druid Kafka ingestion
You can use Druid's Kafka indexing service to ingest messages from your newly created wikipedia topic. To start the service, navigate to the Imply directory and submit a supervisor spec to the Druid overlord as follows:
curl -XPOST -H'Content-Type: application/json' -d @quickstart/wikipedia-kafka-supervisor.json http://localhost:8090/druid/indexer/v1/supervisor
If you are not using a locally running Imply instance:
- Copy the contents of the following listing to a file.
- Modify the value for
bootstrap.serversto the address and port where Druid can access the Kafka broker. - Post the updated file to the URL where your Druid Overlord process is running.
{
"type": "kafka",
"spec" : {
"dataSchema": {
"dataSource": "wikipedia",
"timestampSpec": {
"column": "time",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{
"name": "added",
"type": "long"
},
{
"name": "deleted",
"type": "long"
},
{
"name": "delta",
"type": "long"
}
]
},
"metricsSpec": [],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "HOUR",
"queryGranularity": "NONE",
"rollup": false
}
},
"tuningConfig": {
"type": "kafka",
"reportParseExceptions": false
},
"ioConfig": {
"topic": "wikipedia",
"inputFormat": {
"type": "json"
},
"replicas": 1,
"taskDuration": "PT10M",
"completionTimeout": "PT20M",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
}
}
}
}
When the Overlord successfully creates the supervisor, it returns a response containing the ID of the supervisor. In this case: {"id":"wikipedia-kafka"}.
For more details about what's going on here, check out the Supervisor documentation.
Load data into Imply
Now it's time to launch a console producer for your topic and send some data!
-
Navigate to your Kafka directory.
-
Modify the following command to replace
{PATH_TO_IMPLY}with the path to your Imply directory:export KAFKA_OPTS="-Dfile.encoding=UTF-8"
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wikipedia < {PATH_TO_IMPLY}/quickstart/wikipedia-2016-06-27-sampled.json -
The Kafka indexing reads the events from the topic and ingests them into Druid.
-
Within the Druid console, navigate to the Datasources page to verify that the new
wikipedia-kafkadatasource appears: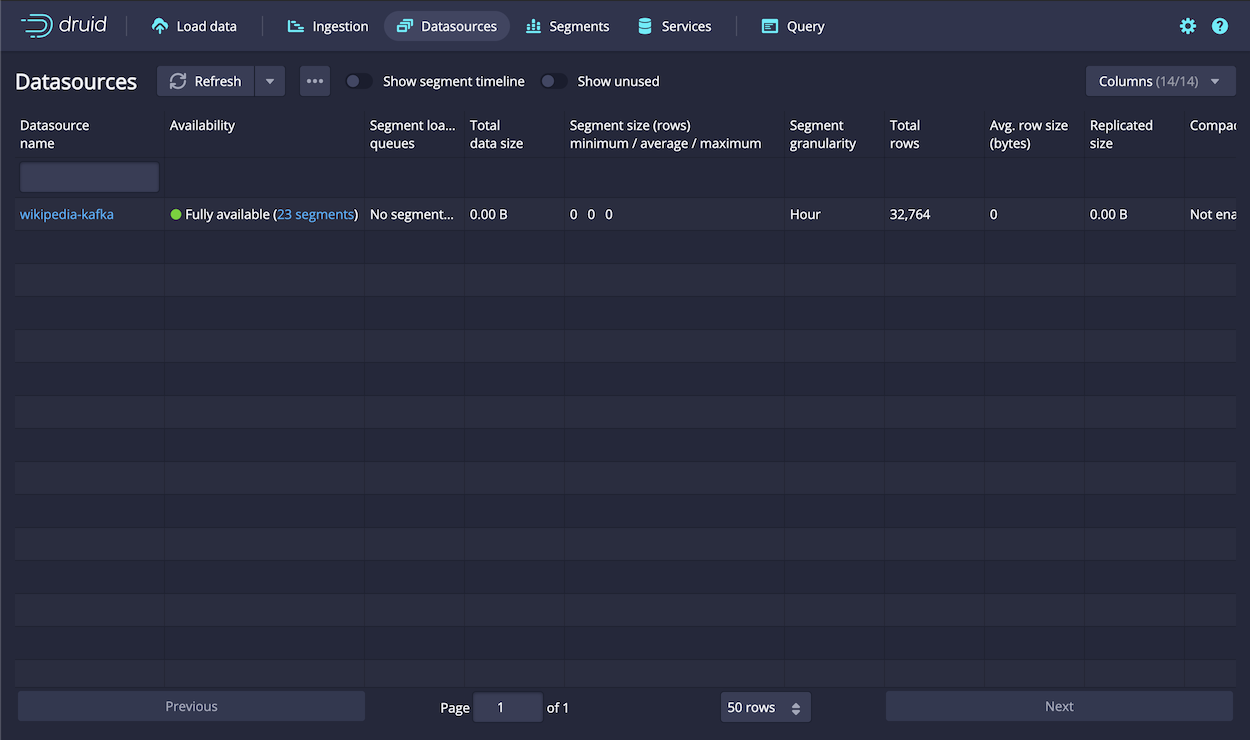
-
Click the Segments link to see the list of segments generated by ingestion. Notice that the ingestion spec specified partitioning to
HOUR, so there is a segment for each hour, around 22 based on the data ingested.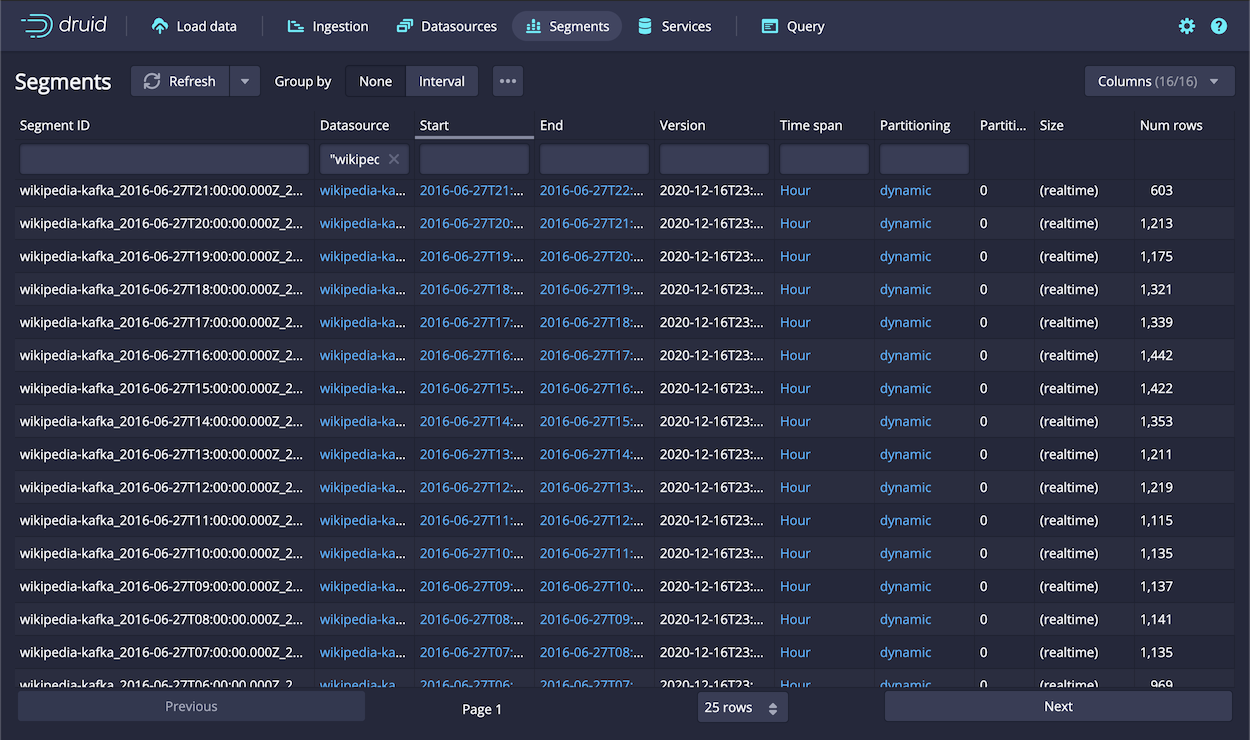
That's it! You can now query the data in the console, but first try ingesting real-time data, as follows.
Load real-time data
Exploring historical Wikipedia edits is useful, but it's even more interesting to explore trends on Wikipedia happening right now.
To do this, you can download a helper application to parse events from Wikimedia's IRC feeds and post them to the wikipedia Kafka topic from the previous step, as follows:
-
From a terminal, run the following commands to download and extract the helper application:
curl -O https://static.imply.io/quickstart/wikiticker-0.8.tar.gz
tar -xzf wikiticker-0.8.tar.gz
cd wikiticker-0.8-SNAPSHOT -
Now run wikiticker, passing
wikipediaas the-topicparameter:bin/wikiticker -J-Dfile.encoding=UTF-8 -out kafka -topic wikipedia -
After a few moments, look for an additional segment of real-time data in the datasource created.
-
As Kafka data is sent to Druid, you can immediately query it. Click Query in the console and run the following query to see the latest data sent by wikiticker, and set a time floor for the latest hour:
SELECT
comment, COUNT(*) AS "Count"
FROM "wikipedia-kafka"
WHERE TIME_FLOOR(__time, 'PT1H') >= TIMESTAMP '2020-12-17'
GROUP BY 1
ORDER BY 2 DESC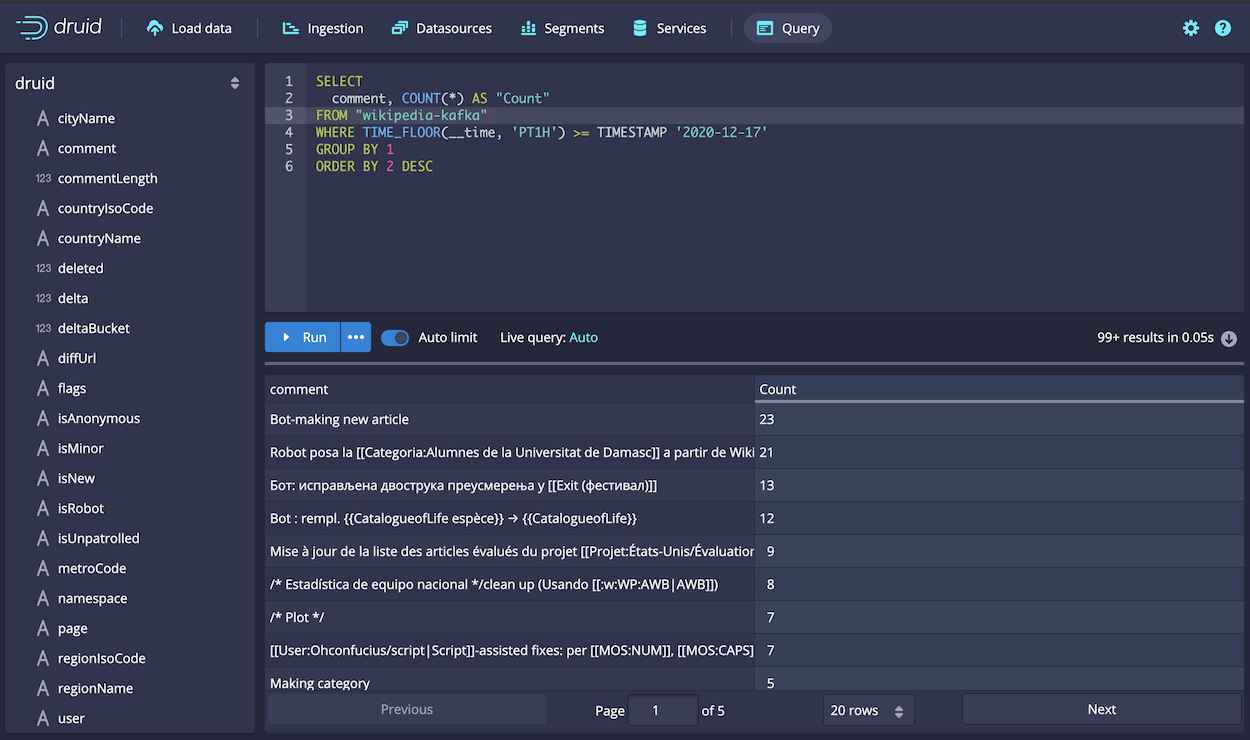
Build a data cube
Next, try configuring a data cube in Pivot:
-
Navigate to Pivot at http://localhost:9095. You should see your
wikipedia-kafkadatasource:
-
Click on the datasource and then click Create a data cube, and click Create when prompted.
-
Click Go to data cube.
-
You can now slice and dice and explore the data like you would any data cube:
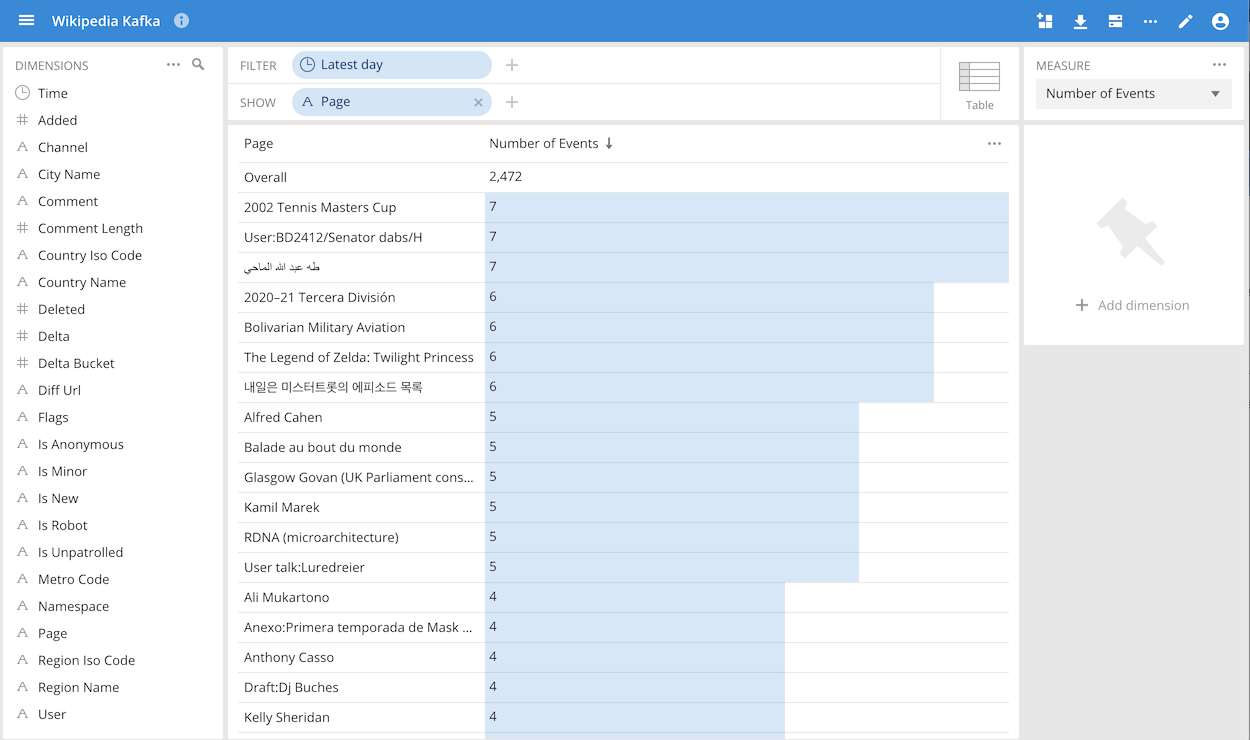
Next steps
So far, you've loaded data using an ingestion spec included in Imply's distribution of Apache Druid®. Each ingestion spec is designed for a particular dataset. You can load your own datasets by writing a custom ingestion spec.
To write your own ingestion spec, you can copy the contents of the quickstart/wikipedia-kafka-supervisor.json file (or copy from the listing above) into your own file as a starting point, and edit it as needed.
Alternatively, use the Druid data loader UI to generate the ingestion spec by clicking Apache Kafka from the Load Data page.
The steps for configuring Kafka ingestion in the data loader are similar to those for batch file ingestion, as described in the Quickstart. However, you use the Kafka bootstrap server as the source, as shown:
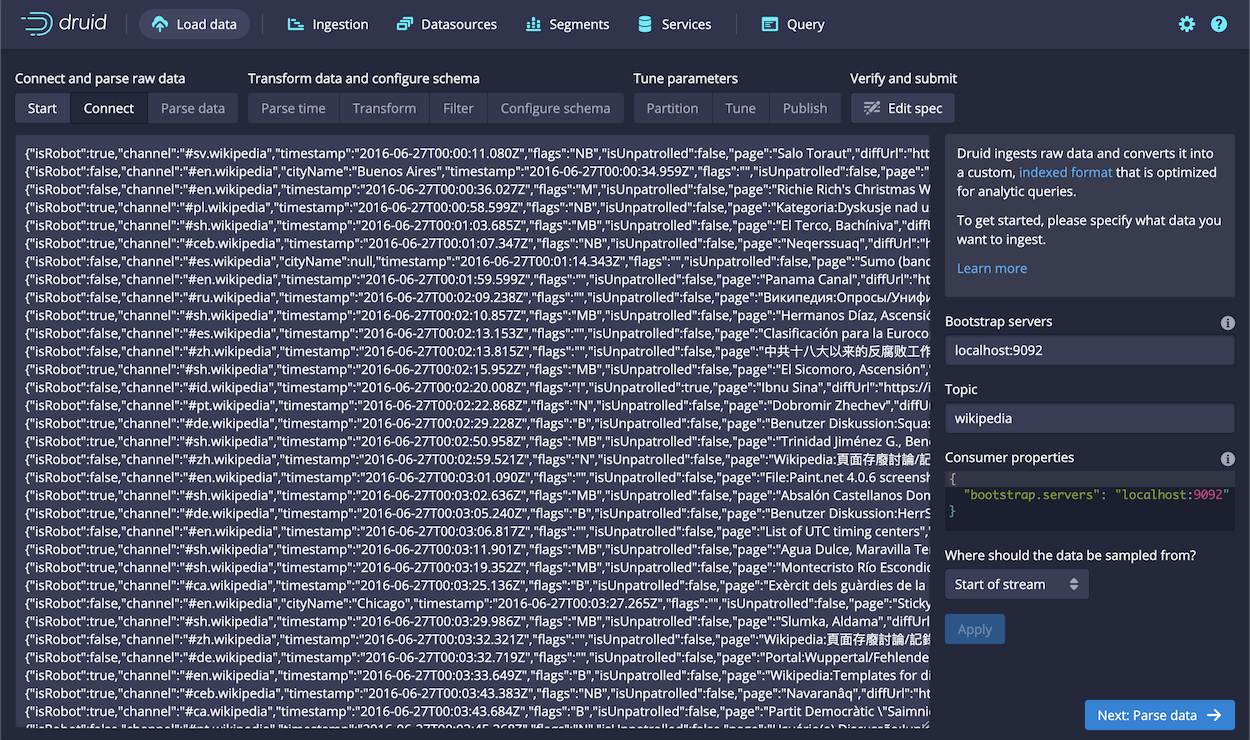
As a starting point, you can keep most settings at their default values. At the Tune step, however, you must choose whether to retrieve the earliest or latest offsets in Kafka by choosing False or True for the input tuning.
When you load your own Kafka topics, Druid creates at least one segment for every Kafka partition for every segmentGranularity period. If your segmentGranularity period is HOUR and you have three Kafka partitions, then Druid creates at least one segment per hour.
For best performance, keep your number of Kafka partitions appropriately sized to avoid creating too many segments.
For more information, see Druid's Supervisor documentation.