Ingestion status reference
Each ingestion job in Imply Polaris provides information on row count metrics. This includes details on the number of rows successfully processed, rows filtered out during ingestion, and any rows that couldn't be ingested due to parsing issues. or unable to be ingested since the row was unable to be parsed.
This topic describes the row count metrics for an ingestion job.
View row count metrics
View the row count metrics for an ingestion job in the job details page.
You can also access these same metrics using the Jobs API. For more information, see View metrics for a job.
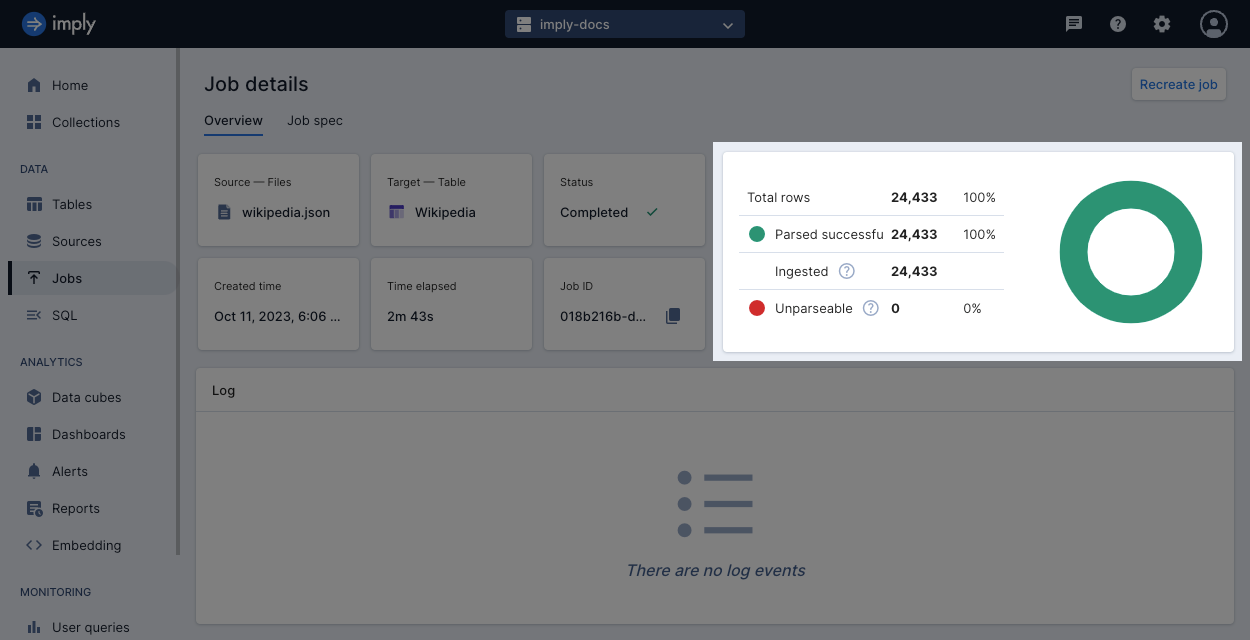
Row count metrics reference
This section describes the row count metrics listed for batch and streaming ingestion jobs.
To limit the number of unparseable rows, you can specify a threshold for parsing exceptions in an ingestion job.
The job fails if the number of parsing exceptions exceeds the threshold.
Set this limit in maxParseExceptions when creating an ingestion job.
Batch ingestion
A batch ingestion job reports the following row count metrics. Polaris deduces batch metrics from the MSQ task report. For more information on MSQ task reports, see the Apache Druid documentation for SQL-based ingestion API.
Parsed successfully: Number of rows processed successfully without parsing errors.
Jobs API response property: numRowsProcessed
Ingested: Number of rows stored in the table.
This value may be fewer than the number of parsed rows when rollup is applied.
Jobs API response property: numRowsPersisted
Unparseable: Number of rows discarded because they could not be parsed.
Jobs API response property: numRowsSkippedByError
Streaming ingestion
Polaris obtains row count metrics from Apache Druid task metrics. For details on Apache Druid task metrics, see Task reference. A streaming ingestion job reports the following row count metrics.
Parsed successfully: Number of rows processed successfully without parsing errors.
Jobs API response property: numRowsProcessed
Apache Druid task metric: processed
Parsed with warnings: Number of rows processed with one or more parsing errors.
This typically occurs when Polaris can parse the input row but detects an invalid type, such as a string value ingested into a numeric column.
Jobs API response property: numRowsProcessedWithWarnings
Apache Druid task metric: processedWithErrors
Unparseable: Number of rows discarded because they could not be parsed.
Jobs API response property: numRowsSkippedByError
Apache Druid task metric: unparseable
Filtered: Number of rows skipped from a streaming ingestion job.
Polaris skips rows for late arriving event data or when a filter expression is defined.
This number does not include any header rows skipped in CSV data.
Jobs API response property: numRowsSkippedByFilter
Apache Druid task metric: thrownAway
Learn more
See the following topics for more information:
- Create an ingestion job for creating and viewing ingestion jobs.
- Metrics reference for more metrics you can track for streaming ingestion.