Configure streaming ingestion
Streaming ingestion jobs in Imply Polaris consume data from a constantly growing stream, such as a stream of one or more Kafka topics. In the ingestion job, you control the point in the stream where Polaris starts consuming data, as well as the acceptable time range for incoming events. This topic describes configuration settings specific to streaming ingestion jobs, specifically:
- Specify the schema to parse Avro or Protobuf data
- Select and reset where Polaris reads from the stream
- Restrict the time range for what data Polaris ingests
- Pause and resume jobs
Add data to your topic or stream before creating an ingestion job. The Polaris UI samples your data and detects the input schema, so you don't have to enter it manually.
To learn how to create an ingestion job, see Create an ingestion job.
For details on streaming ingestion sources, see Ingestion sources overview.
Specify the data schema
A streaming job that ingests events in Avro or Protobuf format requires a schema for Polaris to read your data.
You can specify the schema for the input data inline, where you provide the JSON or Base64-encoded schema itself, or you can create a connection to the schema registry that's associated with the published events. Polaris supports Confluent Cloud for schema registries.
If you published messages using a schema registry, you must create a connection to the schema registry and refer to that connection in the ingestion job. You can't provide an inline schema to read a message that's published with a schema registry.
Specify the schema in your ingestion job as follows:
-
Determine whether you need to provide an inline schema or connect to your schema registry.
-
For an inline schema for Avro format, you should have the JSON object representing the Avro schema. You can paste the JSON inline or upload a file that contains the schema.
-
For an inline schema for Protobuf format, you need the Protobuf descriptor file compiled from your
.protofile. You can useprotocto compile the Protobuf schema into a descriptor file. For example:protoc --include_imports --descriptor_set_out=kttm.desc kttm.proto -
To use an existing schema registry, create a Schema Registry connection.
-
-
In Polaris, go to Jobs > Create job > Insert data.
-
Select a table or create a new table.
-
Select your streaming source and the name of your connection.
-
Specify the schema:
-
For an Avro inline schema, upload or paste the schema.
-
For a Protobuf inline schema, upload the descriptor file.
If your schema contains more than one message type, enter the type that describes the data. Otherwise, Polaris uses the first message type in the descriptor.
-
For an existing schema registry, click Connect to registry then the name of the connection.
-
-
Polaris samples data from the stream and parses it with the given schema. Click Continue.
-
Map your input fields to table columns. You can also configure transforms, limit the source data using filters, and select the offset for where in the stream to start data ingestion.
-
Click Start ingestion.
To use the Polaris API to create an ingestion job, see Specify data schema by API.
Select offset for streaming ingestion
The offset controls where Polaris starts to consume data from a stream, whether from the earliest or latest point of a stream.
When creating a streaming job, you select the offset in the Map source to table step of the ingestion job. Select one of the following offset options:
- Beginning: Ingest all data starting from the earliest offset. The data is subject to the message rejection period. By default, Polaris only ingests events with timestamps within the last 30 days. To change this period, see Reject early or late data.
- End: (default) Ingest events from the latest offset. This ingests data sent to the topic after Polaris begins the ingestion job.
The following screenshot shows the offset selection for a table:
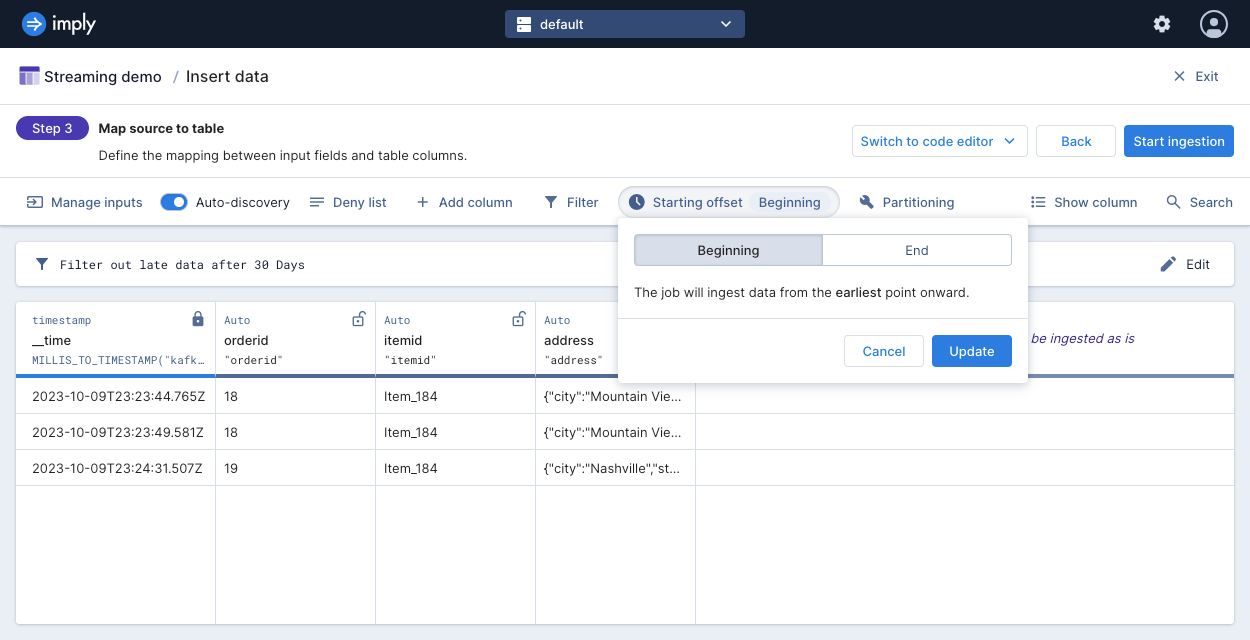
The following diagrams show how the starting offset setting affects the ingestion of data added to a stream before and after starting an ingestion job:
Reset streaming job offset
For a given table and either a topic or stream, Polaris preserves the reading checkpoint of the topic or stream. This behavior applies even if you use a new connection or ingestion job. If you have the same topic and table combination as a previous ingestion job, Polaris maintains the reading checkpoint. But it may no longer be the earliest or latest offset. Polaris only resets the reading checkpoint when the table has a new streaming ingestion job that reads from a different topic or stream.
You may need to reset the offset when either of the following situations occur:
- The topic was deleted and recreated, so the consumer offset restarted.
- Data that was previously read from the topic expired or got deleted, so the consumer offset expired.
Reset the reading checkpoint in order to ingest from your selected offset. The reset only applies to streaming ingestion jobs that are currently running.
When you reset the offset, the ingestion job may omit or duplicate data from the stream.
- If you select the end offset and then reset the job, some data may have entered the stream before you applied the reset. This may result in missing data between the previously stored consumer offset and the latest offset. Consider a batch ingestion job to backfill any missing data.
- If you select the beginning offset and then reset the job, Polaris may ingest data that was already ingested, leading to duplicate data. Consider a replace data job to overwrite the time period with duplicate data with the correct data.
To reset the offset, do the following:
- Navigate to the Jobs page from the left navigation pane.
- Open the streaming job you want to reset.
- Select Manage > Reset offset.
- Polaris displays a confirmation dialog. Click Hard reset to proceed.
After the reset, Polaris ingests streaming data from your selected offset.
To use the API to reset the offset, see Reset streaming job offset by API.
Reject early or late data
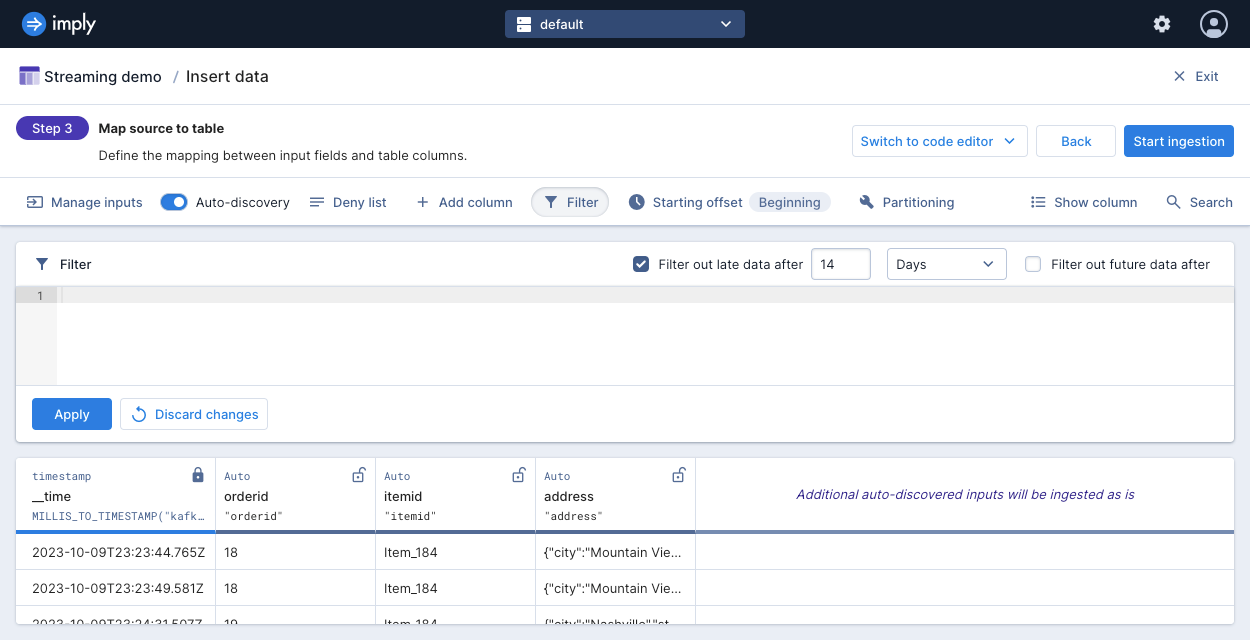
You can set early or late message rejection periods to reject data that arrives earlier or later than a given period, relative to the current time. In the default event timestamp requirement, Polaris does not ingest data older than 30 days and data that's more than 2000 days into the future. Polaris evaluates event timestamps after applying any transforms.
To configure the message rejection period, in the Map source to table step of the ingestion wizard, select Filter from the menu bar and select the option to filter out late data or future data.
The following screenshot shows a job configured to ingest data that has timestamps no older than the past fourteen days:
Pause and resume jobs
You can pause (suspend) a streaming ingestion job as well as resume its ingestion.
When you pause a job, the job execution status changes to Suspended. You can view a job's status in the job details page.
For a streaming ingestion job, the Suspended job status is different than the Idle job status. A job turns idle when it doesn't have data to ingest. In this case, the job automatically resumes with incoming data. A job is only suspended when explicitly requested by the user. The user must resume the job for it to continue.
To pause or resume a job, do the following:
-
Go to the Jobs page from the left navigation pane.
-
Select the job.
-
Click Suspend job to pause a running job. Click Resume job to resume a paused job.
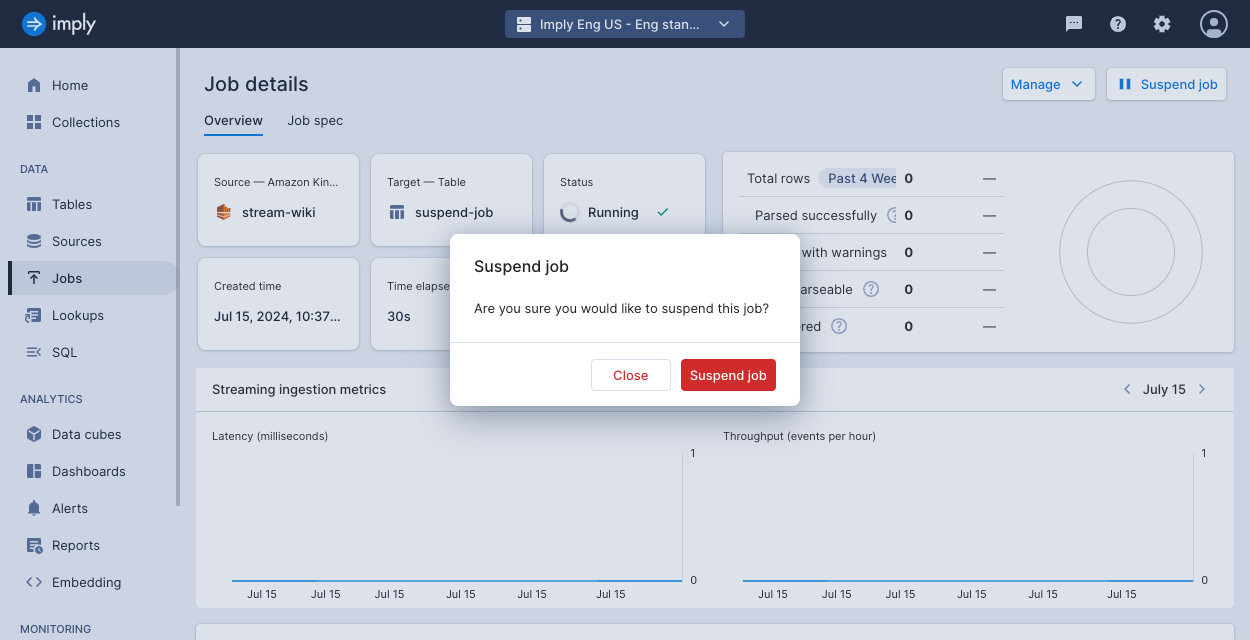
-
Confirm your choice.
To do this using the API, see Pause or resume a job by API.
Learn more
See the following topics for more information:
- Billing: Data ingestion for how data ingestion is billed in Polaris.
- Create an ingestion job for more details on ingestion jobs.
- Manage jobs to view and manage your jobs.
- Ingestion sources overview for reference on sources for data ingestion.
- Filter data to ingest for applying additional filters in ingestion.
- Ingest streaming records and metadata for ingesting both event data and metadata.