Introduction to data rollup
Modern day applications emit millions of events in streaming data per day. As data accumulates, it increases the storage footprint, often leading to higher storage costs and decreased query performance. Imply Polaris uses the Apache Druid data rollup feature to aggregate raw data at predefined intervals during ingestion. By decreasing row counts, rollup can dramatically reduce the size of stored data and improve query performance.
This topic provides an overview of data rollup in Polaris.
Data rollup
Rollup is a form of time-based data aggregation. It combines multiple rows with the same timestamp and dimension values into segments, resulting in a condensed data set. Rollup is most effective when the data has low cardinality. If the data has high cardinality, meaning there are a large number of distinct values in the dimension, fewer rows are rolled up.
Rollup only applies to aggregate tables. When you select the detail table type, Polaris stores each record as it is ingested, without performing any form of aggregation.
The following are optimal scenarios to create an aggregate table with rollup:
- You want optimal performance or you have strict space constraints.
- You don't need raw values from high-cardinality dimensions.
Conversely, create a detail table without rollup when any of the following conditions hold:
- You want to preserve results for individual rows.
- You don't have any measures that you want to aggregate during the ingestion process.
- You have many high-cardinality dimensions.
Time granularity
The time granularity determines how to bucket data across the timestamp dimension using UTC time—days start at 00:00 UTC. By default, Polaris buckets input data at millisecond granularity.
Simple granularities
Polaris supports the following time granularity options to bucket input data:
| Time granularity | ISO 8601 notation | Example |
|---|---|---|
| Millisecond | — | 2016-04-01T01:02:33.080Z |
| Second | PT1S | 2016-04-01T01:02:33.000Z |
| Minute | PT1M | 2016-04-01T01:02:00.000Z |
| 15 minute | PT15M | 2016-04-01T01:15:00Z |
| 30 minute | PT30M | 2016-04-01T01:30:00Z |
| Hour | PT1H | 2016-04-01T01:00:00.000Z |
| Day | P1D | 2016-04-01T00:00:00.000Z |
| Week | P1W | 2016-06-27T00:00:00.000Z |
| Month | P1M | 2016-06-01T00:00:00.000Z |
| Quarter | P3M | 2016-04-01T00:00:00.000Z |
| Year | P1Y | 2016-01-01T00:00:00.000Z |
You can also set the rollup granularity to all, which allows you to group data by dimensions regardless of the timestamp.
This option is primarily useful for non-time-series data.
Period granularities
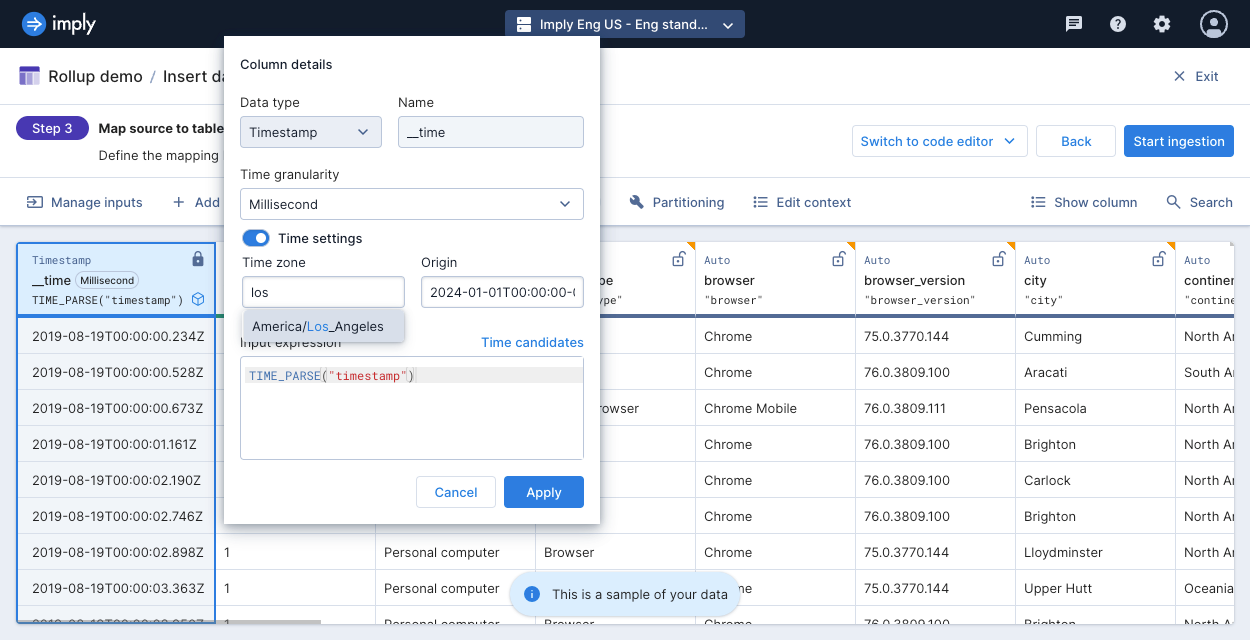
In addition to setting simple granularities such as day, month, or year, you can set an arbitrary period length such as six months. You can also customize the time zone and the time origin from which to evaluate period boundaries.
For the time zone, provide a valid time zone from the tz database, such as America/Los_Angeles.
The default time zone is UTC.
For the time origin, specify a date in ISO 8601 format, such as 2024-01-01T00:00:00-00:00.
The default origin is 1970-01-01T00:00:00 in the given time zone.
Set rollup granularity
Ensure that you have an aggregate table in order to configure its rollup granularity. You can set or change the rollup for a table:
- When you create an ingestion job, in the Map source to table step.
- From the Edit table page. To get to this page, go to a table, then click Manage > Edit table.
In the UI, select Edit on the primary timestamp column, __time, then select an option from the Time granularity field.
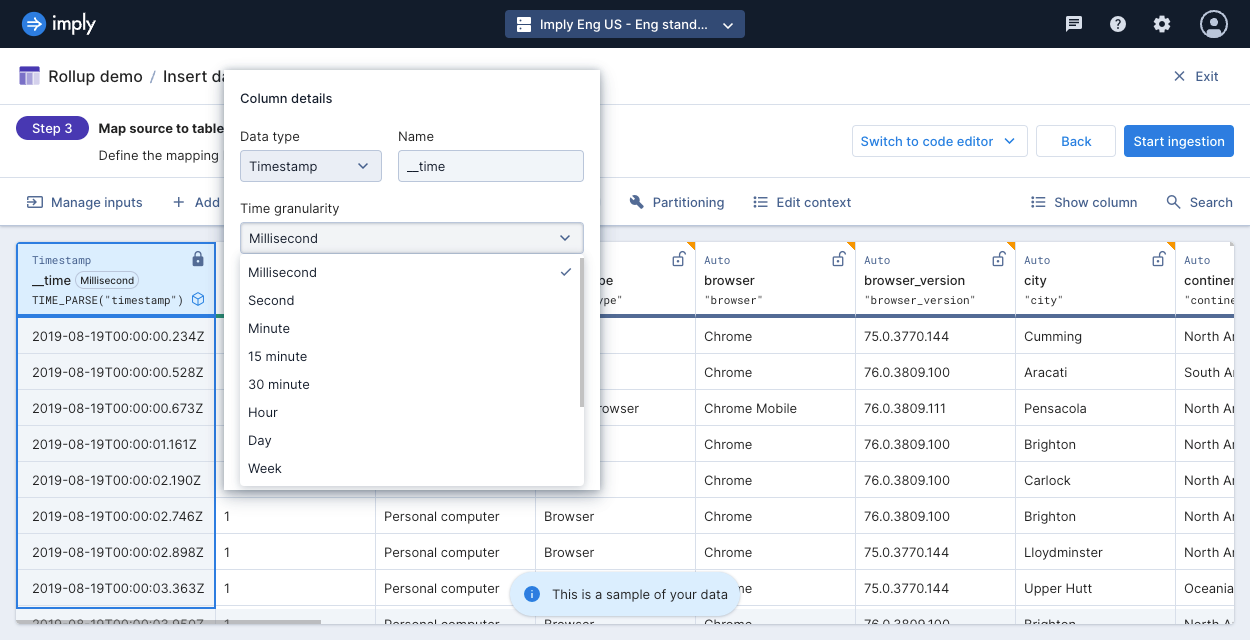
To customize the time zone and origin time for period boundaries, click the Time settings toggle, and enter the time zone and origin. Start typing a time zone to see a list of available options.
You cannot set a custom duration for rollup granularity using the UI.
Instead, set this when creating or updating a table using the API with the table's queryGranularity property.
For more information, see Tables v1 API.
Example
The following example shows how to ingest data into an aggregate table and specify its rollup time granularity. The dataset is a sample of network flow event data, representing packet and byte counts for an IP traffic that occurred within a particular second.
To ingest data into an aggregate table and specify its rollup granularity, follow these steps:
- Download this JSON file containing the sample input data.
- Click Tables from the left navigation menu of the Polaris UI.
- Click Create table.
- Enter a unique name for your table, select the Aggregate table type, and select the Strict schema mode. Click Next.
- From the table view, click Load data > Insert data and select the file you downloaded,
rollup-data.json. - Click Next > Continue.
- On the Map source to table step, click on the timestamp dimension, then click Edit.
- In the timestamp dialog, select
Minutefrom the Rollup granularity drop-down. This tells Polaris to bucket the timestamps of the original input data by minute. - Click Start ingestion.
Your table should look similar to the following:
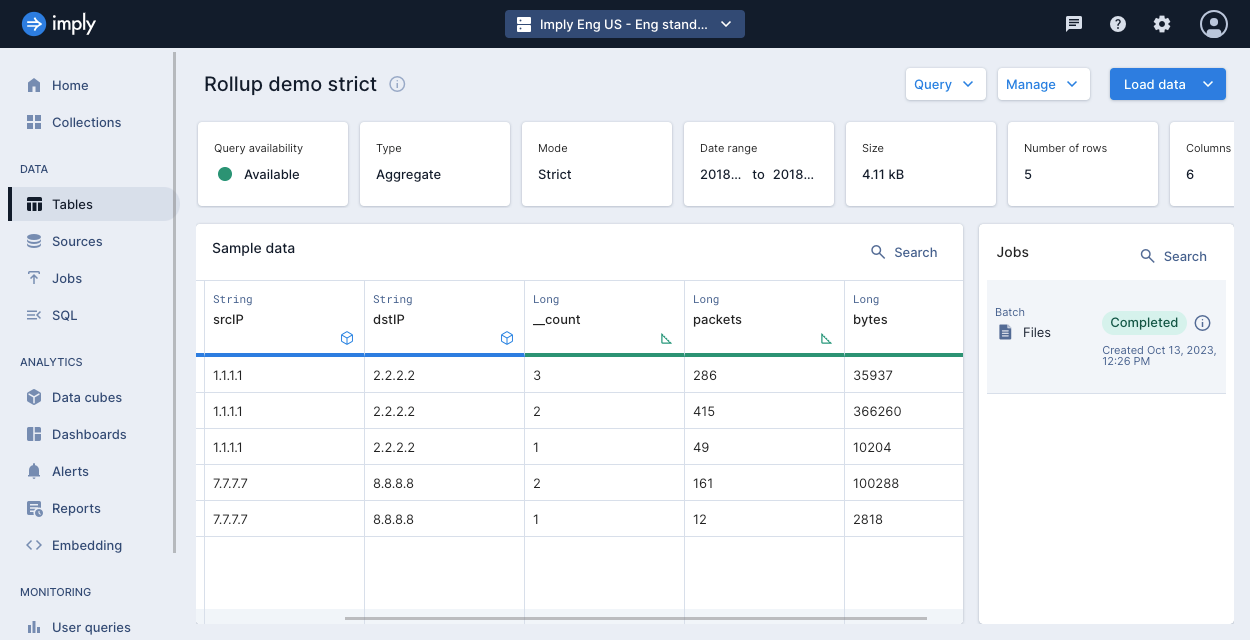
The input data has nine rows, but with rollup applied, the table stores five rows.
All aggregate tables automatically include a __count measure. This measure counts the number of source data rows that were rolled up into a given row.
For more information, see Schema measures.
The following events were aggregated:
-
Events that occurred during
2018-01-01 01:01:{"timestamp":"2018-01-01T01:01:35Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":20,"bytes":9024}
{"timestamp":"2018-01-01T01:01:51Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":255,"bytes":21133}
{"timestamp":"2018-01-01T01:01:59Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":11,"bytes":5780} -
Events that occurred during
2018-01-01 01:02:{"timestamp":"2018-01-01T01:02:14Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":38,"bytes":6289}
{"timestamp":"2018-01-01T01:02:29Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":377,"bytes":359971} -
Events that occurred during
2018-01-02 21:33:{"timestamp":"2018-01-02T21:33:14Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":38,"bytes":6289}
{"timestamp":"2018-01-02T21:33:45Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":123,"bytes":93999}
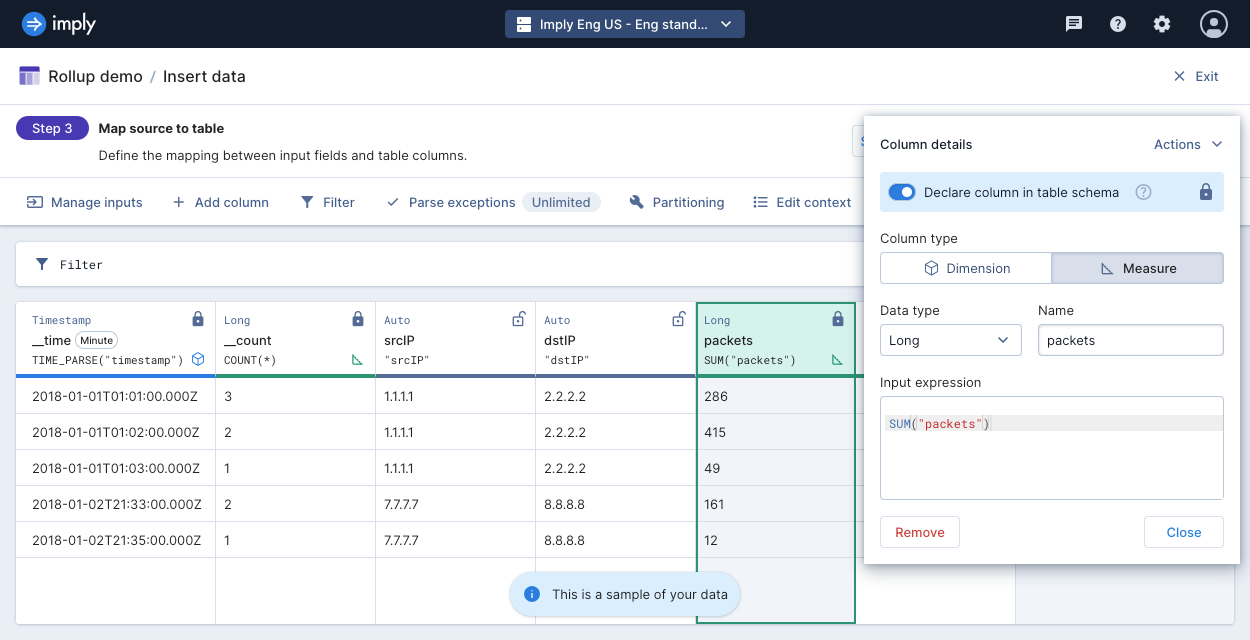
If your table contains the flexible schema mode, Polaris treats all columns as dimensions. Since rollup only applies when rows have the same timestamp and dimension values, no rows will be rolled up in this example.
To get the same behavior in flexible mode, while on the Map source to table step,
edit the packets column as follows:
- Declare it in the table schema
- Select the Measure column type
- Define the input expression
SUM("packets")
Apply the same actions to the bytes column, using the input expression SUM("bytes").
Before you start ingestion, your table should look like the following:
Limitations
The following restrictions apply to rollup:
- Rollup is set for aggregate tables only. Tables are either aggregate or detail at creation. Once a table is created, you cannot change its type.
- Once you add data to an aggregate table and specify its rollup granularity, you can only make the granularity coarser—for example,
MinutetoHour. Polaris makes the granularity change during compaction. If an aggregate table does not contain data and there is not an active ingestion job associated with the table, you can change the rollup granularity to a finer granularity—for example,HourtoMinute.
Learn more
See the following topics for more information:
- Table schema for the different data types for Polaris columns.
- Tables v1 API for reference on working with tables in Polaris.
- Ingestion sources overview for the available sources for ingestion in Polaris.