Parse data using regular expressions
To ingest structured data that's not one of the supported formats, you can use regular expressions (regex) to parse the data. To use regex format, you supply a regex pattern containing one or more capturing groups. Each capturing group represents a column of input data. You also provide a list of column names for the input field names.
The regex format is available anywhere you specify data format settings, such as ingesting from a file or an event stream. You can also use the regex format to parse Kafka keys for ingestion. For details on ingesting Kafka keys, see Ingest streaming records and metadata.
Keep the following in mind when using the regex format:
- Each capturing group must be contained within parentheses. For example, use
(.*)to capture everything. - You must supply one column name for each capturing group.
- When supplying a regex pattern through the API, escape special characters such as
\to ensure valid JSON. - When using regex to parse Kafka keys, only specify a single capturing group.
Ingest regex data
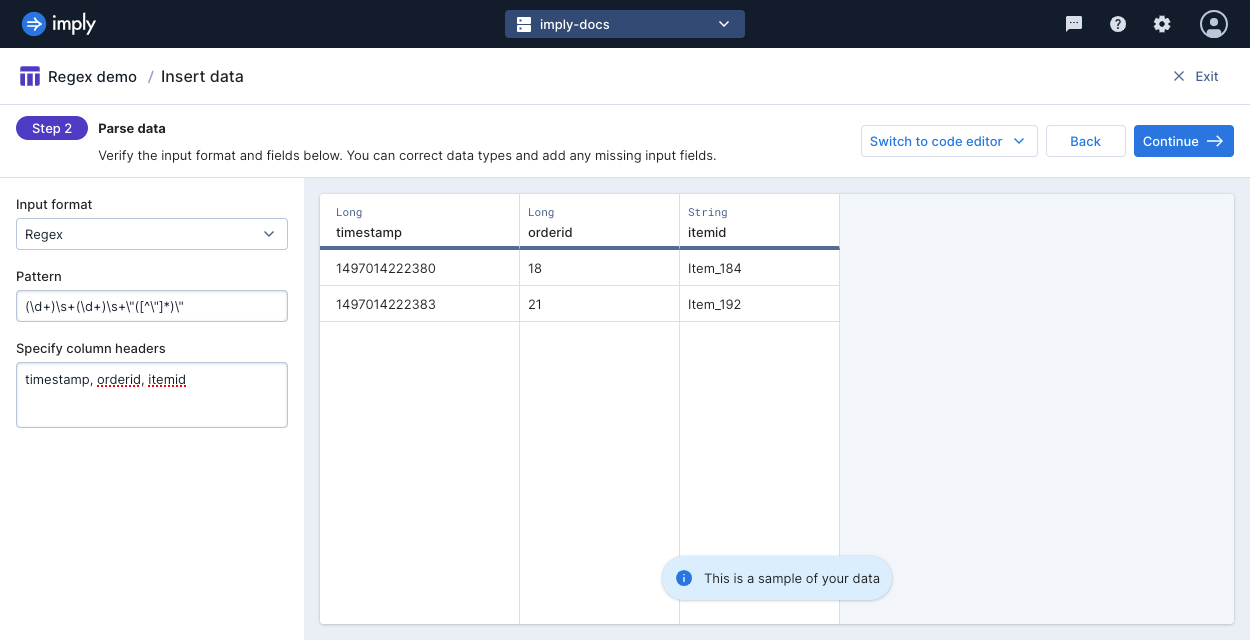
You specify the input format in the Parse data stage of creating an ingestion job.
Select Regex in the Input format drop-down menu:
Examples
This section goes through example use cases for the regex format.
File with order details
Consider a file that contains the following data:
1497014222380 18 "Item_184"
1497014222383 21 "Item_192"
The first column represents the time an order was made. The second column represents the ID of the order. The third column represents the ID of the item ordered.
This data will always be constrained to contain digits for the first column, digits for the second column, and a variable number of characters within quotation marks for the third column. There may be one or more whitespace characters between each column.
The following regex pattern meets all of the criteria:
(\d+)\s+(\d+)\s+"([^"]*)
The third capturing group only captures the content within, but not including, the quotation marks.
When using the Polaris API, the JSON job spec would contain the following source format settings:
"formatSettings": {
"format": "regex",
"pattern": "(\\d+)\\s+(\\d+)\\s+\"([^\"]*)\"",
"columns": ["ordertime","orderid","itemid"]
}
Kafka key with email addresses
Consider a Kafka message whose value has the actual payload of the message and whose key contains additional information that supplements the data. For example, the Kafka key contains the email address of the person associated with the event. In this case, you want to focus on parsing the Kafka key for ingestion.
Key: "user1@example.com"
The following regex pattern ingests the full email address as is, including the quotation marks:
(.*)
When using the Polaris API, the format settings of the JSON job spec may look like the following:
"formatSettings": {
"valueFormat": {
"flattenSpec": null,
"format": "nd-json"
},
"headerFormat": null,
"headerLabelPrefix": "kafka.header.",
"keyColumnName": "keylabel",
"keyFormat": {
"columns": [
"keylabel"
],
"pattern": "(.*)",
"format": "regex"
},
"timestampColumnName": "kafka.timestamp",
"format": "kafka"
},
For another use case, you want to parse the email address to extract the username. The following example captures the username only:
\"?([\\w.%+-]+)@[\\w.-]+\"?
The pattern contains basic checks for valid characters in email addresses.
The ingested value is just user1.
For more information on ingesting Kafka keys, see Parse event key.
Note that if your regex for parsing the Kafka key contains multiple capturing groups, Polaris only retains the first group. You must still provide a column name for each group.
Learn more
For more information about ingestion jobs, see Create an ingestion job.
For other supported formats, see Supported data and file formats.