Connect to Confluent Schema Registry
When you ingest streaming data in Avro or Protobuf format, you need to provide additional schema information for Polaris to parse the input data. You can provide this schema "inline" directly in the job request, or through a connection to Confluent Schema Registry.
If you published messages using a schema registry, you must create a connection to the schema registry and refer to that connection in the ingestion job. You can't provide an inline schema to read a message that's published with a schema registry.
For an end-to-end guide ingesting with the Confluent Schema Registry, see Guide for Confluent Cloud ingestion with Confluent Schema Registry.
Create a connection
Create a Confluent Schema Registry connection as follows:
- Click Sources from the left navigation menu.
- Click Create source > Confluent Schema Registry.
- Enter the connection information.
- Click Create connection.
The following screenshot shows an example connection created in the UI. For more information, see Create a connection.
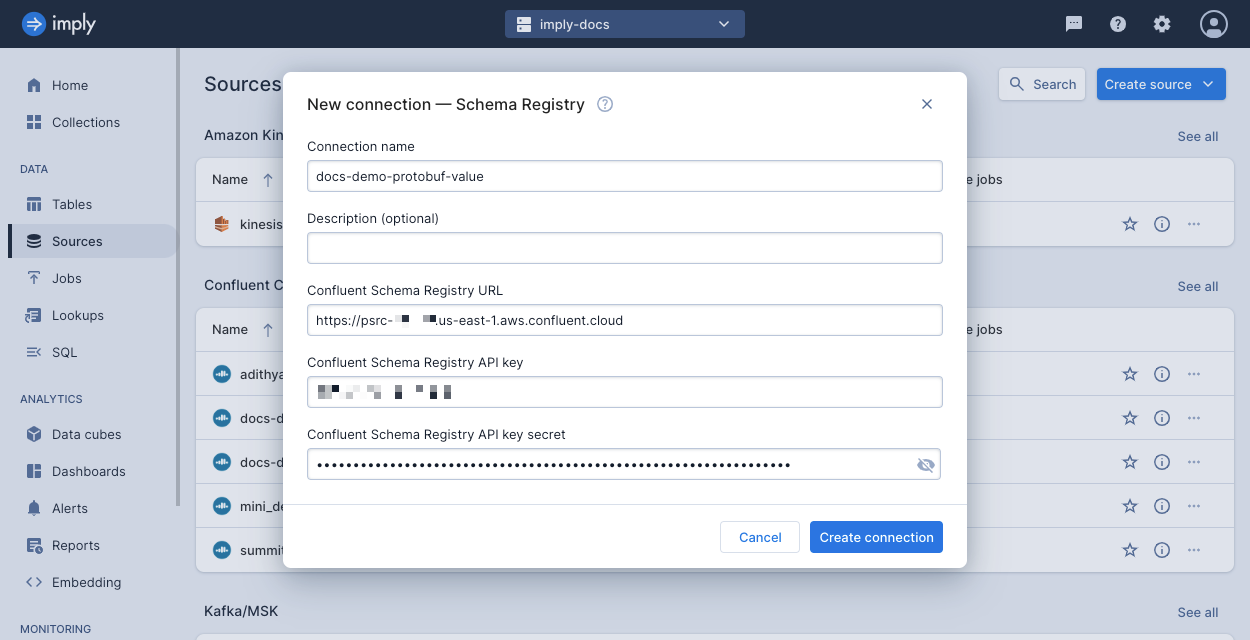
For information on using the Confluent Schema Registry connection, see Specify the data schema.
Connection information
Follow the steps in Create a connection to create the connection.
The connection requires the URLs of the Schema Registry. Supply one or more Schema Registry endpoints.
For example, https://psrc-xxxxx.us-east-1.aws.confluent.cloud.
Authentication
To grant Polaris access to your schemas, you need a Confluent Schema Registry API key. To create an API key, refer to the Confluent documentation.
In the Confluent Schema Registry connection, input the key and secret for the API key.
Learn more
See the following topics for more information: