Aggregate to earliest or latest value
When you ingest data into Imply Polaris, you can aggregate, or roll up, individual records to store as a single record. For a string or numeric input field, you can use an input expression to store the input field's value that corresponds to the earliest or latest timestamp for the set of aggregated rows. The ingested field populates a measure in an aggregate table.
This topic shows you how to ingest the earliest or latest value of an input field into a table.
Function reference
Use the following functions to aggregate the earliest or latest data for a given input field:
EARLIEST_BY(expr, timestampExpr)LATEST_BY(expr, timestampExpr)
The first parameter is the string or numeric input field to aggregate. The second parameter is the timestamp expression to evaluate for the earliest or latest time.
To generate the timestamp expression:
- If you have a string input field with ISO 8601 timestamps, use the function
TIME_PARSE(expr). - If you have a long input field with milliseconds since Unix epoch timestamps, use the function
MILLIS_TO_TIMESTAMP(expr).
The result of the aggregation is a JSON object that resembles the following:
{
"lhs": 1704070018771,
"rhs": 5
}
The lhs value is the reference time for the aggregation in milliseconds since Unix epoch. The rhs value is the aggregated result.
For details on each function, including an optional parameter to control how many bytes to allow for aggregation, see Druid SQL aggregation functions.
Polaris does not support ingesting with the EARLIEST and LATEST aggregation functions.
Use these functions on the aggregated values at query time.
If you use EARLIEST_BY and LATEST_BY at query time, Polaris only evaluates __time for the reference timestamp, regardless of the timestampExpr argument.
Example
Consider the following simplified example with three input fields, event_time which gets mapped to __time, response_time, and score. When the following data is rolled up by DAY, all of the records get aggregated to a single table row.
event_time | response_time | score |
|---|---|---|
2024-01-01T00:46:58.771Z | 2024-01-04T00:46:58.771Z | 5 |
2024-01-01T01:46:58.771Z | 2024-01-03T00:46:58.771Z | 2 |
2024-01-01T02:46:58.771Z | 2024-01-09T00:46:58.771Z | 9 |
2024-01-01T03:46:58.771Z | 2024-01-06T00:46:58.771Z | 0 |
The following input expression for the score measure stores the value 5:
EARLIEST_BY("score", TIME_PARSE("event_time"))
The following input expression for the score measure stores the value 0:
LATEST_BY("score", TIME_PARSE("event_time"))
The following input expression for the score measure stores the value 2:
EARLIEST_BY("score", TIME_PARSE("response_time"))
The following input expression for the score measure stores the value 9:
LATEST_BY("score", TIME_PARSE("response_time"))
Ingest earliest or latest value
This section shows you how to apply input expressions to ingest the earliest and latest values based on the primary timestamp and another reference timestamp.
You ingest the data shown in the preceding example and create four additional measures in the table:
score_earliest: Stores the earliest value ofscorewith respect toevent_time.score_latest: Stores the latest value ofscorewith respect toevent_time.score_response_earliest: Stores the earliest value ofscorewith respect toresponse_time.score_response_latest: Stores the latest value ofscorewith respect toresponse_time.
Follow along with the example using these steps:
-
Download this CSV file containing the sample input data.
-
Click Tables from the left navigation menu of the Polaris UI.
-
Click Create table.
-
Enter
Earliest demo, select the Aggregate table type, and select the Flexible schema mode. Click Next. -
From the table view, click Load data > Insert data.
-
Click the Files source. Upload and select the file you downloaded,
earliest.csv. -
Click Next > Continue.
-
In the Map source to table step, click Add column from the menu bar.
-
In the Column details dialog, complete the following:
- Click the toggle to declare the column.
- Column type: Measure
- Data type: Long string pair
- Name:
score_earliest - Input expression:
EARLIEST_BY("score", TIME_PARSE("event_time"))
-
Repeat the previous step with the following names and input expressions:
score_latest:LATEST_BY("score", TIME_PARSE("event_time"))score_response_earliest:EARLIEST_BY("score", TIME_PARSE("response_time"))score_response_latest:LATEST_BY("score", TIME_PARSE("response_time"))
-
Hover over the
response_timecolumn and click Edit > Remove. Repeat this step to remove thescorecolumn. -
Hover over the primary timestamp column, and click Edit. In the timestamp dialog, select
Dayfrom the Time granularity drop-down. This tells Polaris to bucket the timestamps of the original input data by day. -
Click Apply. Your table should resemble the following:
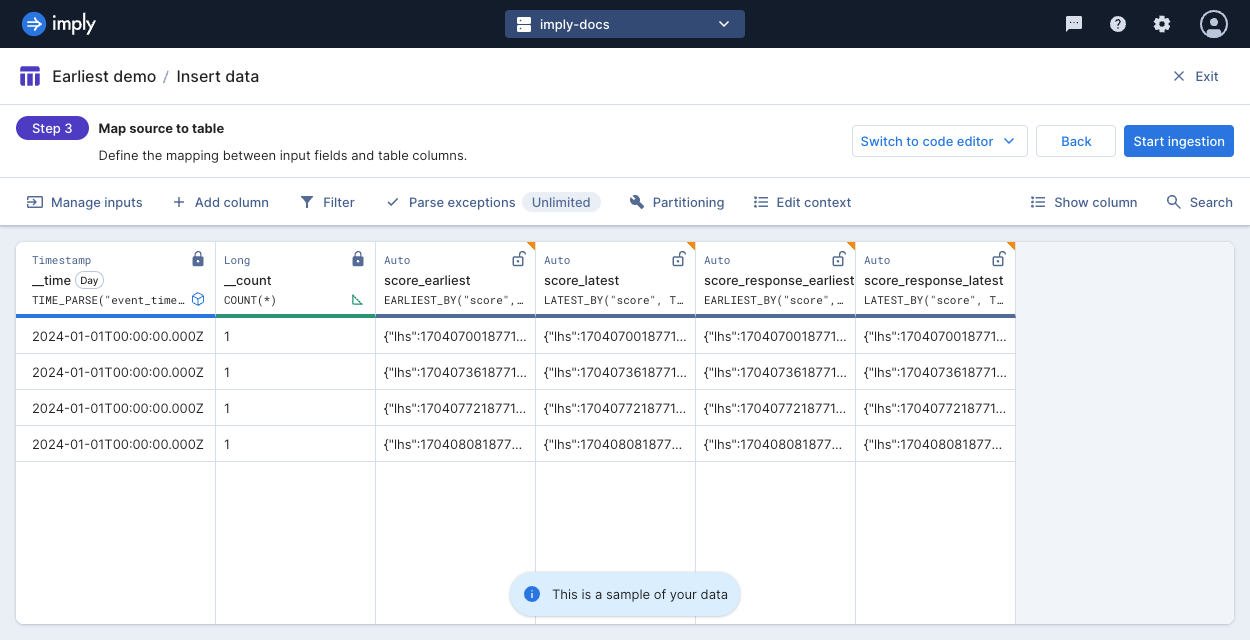
- Click Start ingestion.
- View the table you just ingested. Note that all four input rows were aggregated to a single row in the table. The values of the new columns match the aggregated values described in the example.
Learn more
For more information, see the following topics:
- Introduction to tables for details on aggregate tables.
- Introduction to data rollup for how Polaris aggregates raw data during ingestion.
- Map and transform data with input expressions for details on input expressions and supported aggregation functions.