Data cube dimensions
Data cube dimensions correspond to columns in your source table or transform data in your source table. In a data cube, you can display and filter data by dimension.
You can drag dimensions into the filter bar, show bar, and pinboard panels to interactively explore and analyze data.
In the following example, the data cube view is filtered by the Time dimension, __time in the original table. It shows the Number of Events during the latest 6 hours by Country Name:
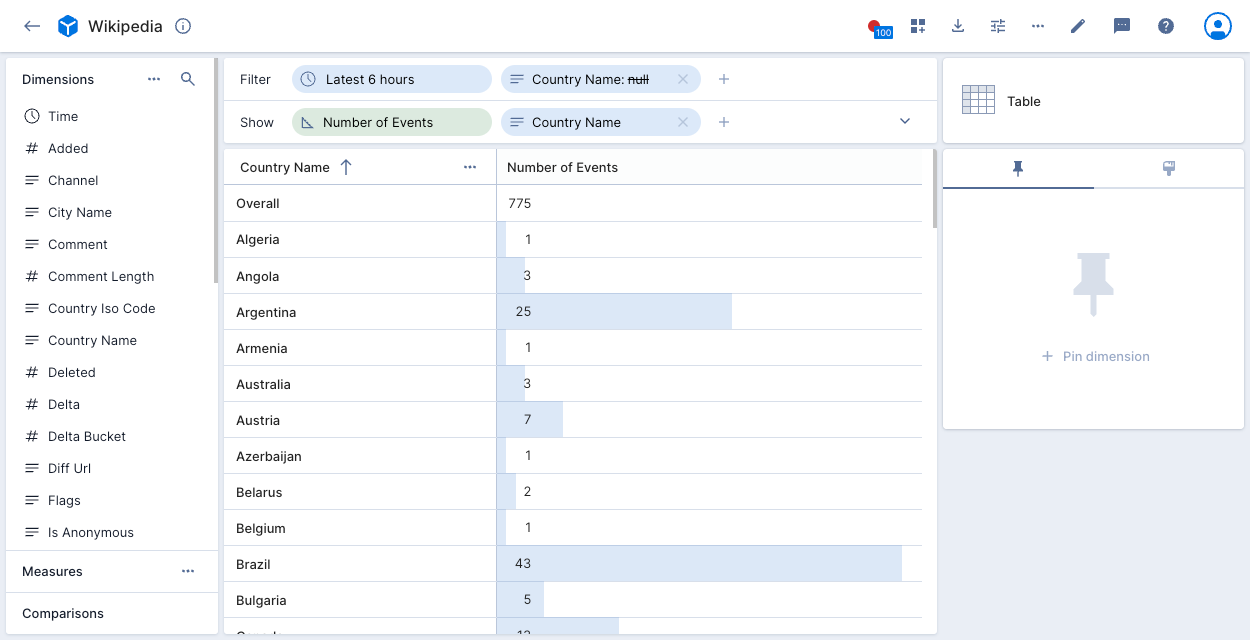
Number of Events is a data cube measure. In contrast to a dimension, a measure represents an output of an aggregation function applied to a corresponding list of dimensions.
Click on a dimension in the left pane to activate the dimension preview menu.
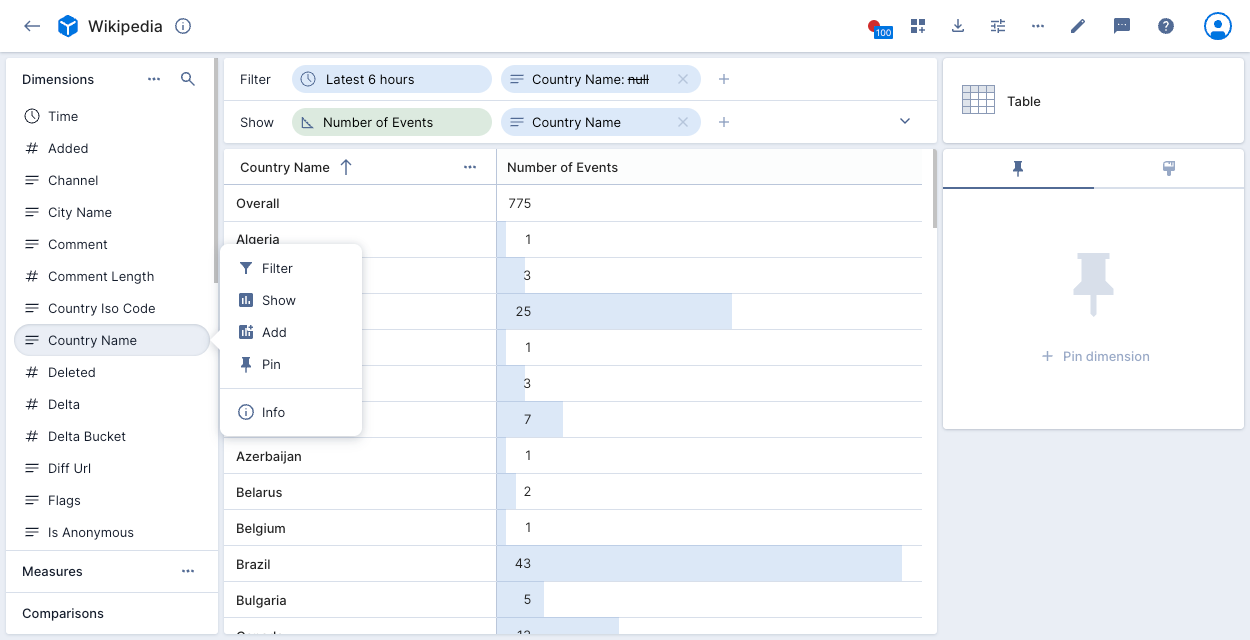
After you drag a dimension into the show bar, click the dimension to set the following options:
- Sort by: Sort the dimension in ascending or descending order.
- Limit: Limit the number of values to display. For example, selecting
Limit:5in the above example displays five countries with the highest number of events.
The limit defaults to 1000 for string type dimensions and 5000 for numeric type dimensions. - Others: If you set a Limit, show or hide a row that displays the sum total of all values omitted by the limit.
Create a dimension
To create a new dimension, go into data cube edit mode and click the Dimensions tab.
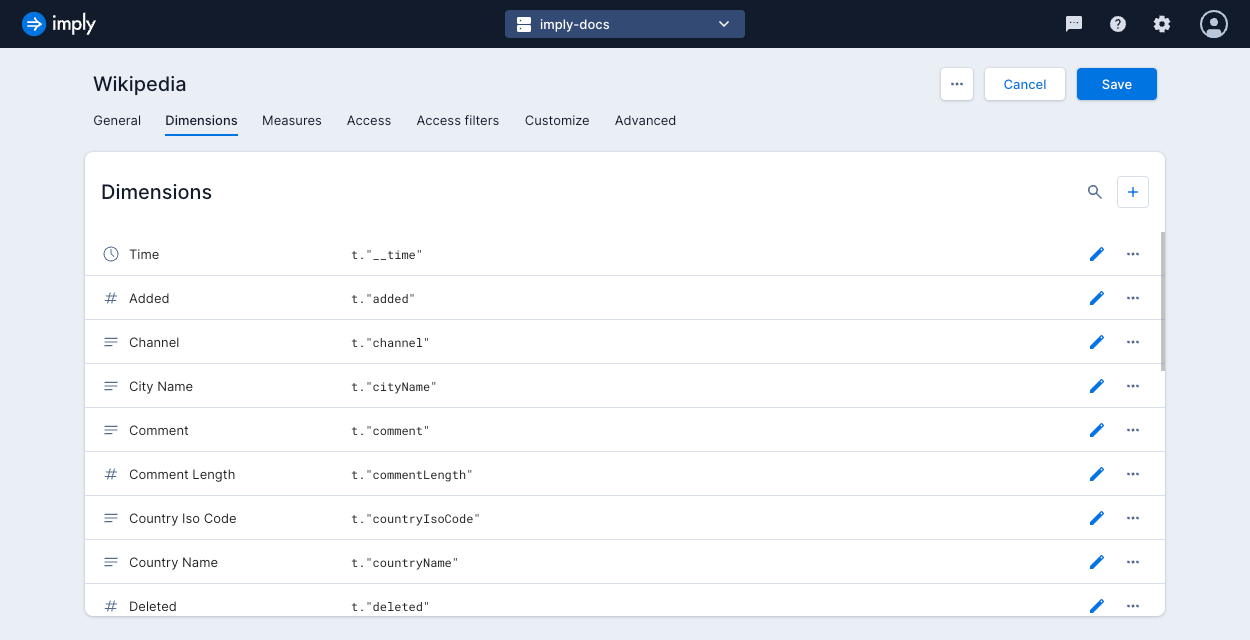
Click the plus icon to create a dimension and complete the following fields:
- Name: Name of the dimension.
- Description: Description of the dimension to appear in the dimension's Info pop-up window.
- Formula: Select one of the following:
- Basic: A basic dimension directly represents a column from the source table. Select the column.
- Custom: A custom dimension transforms data from the source table. Enter a Druid SQL expression as the dimension's formula. See Custom dimension example for more information.
- Type: Select the data type of the dimension. Polaris will present extra fields depending on the type. See Dimension types for more information and examples.
- Format as URL: Format the dimension as a URL. See URL dimensions for more details.
When you've completed the configuration, click Save to save the dimension.
Edit a dimension
To edit a dimension, go into data cube edit mode and click the Dimensions tab. Click the pencil icon next to a dimension and update the dimension properties as required.
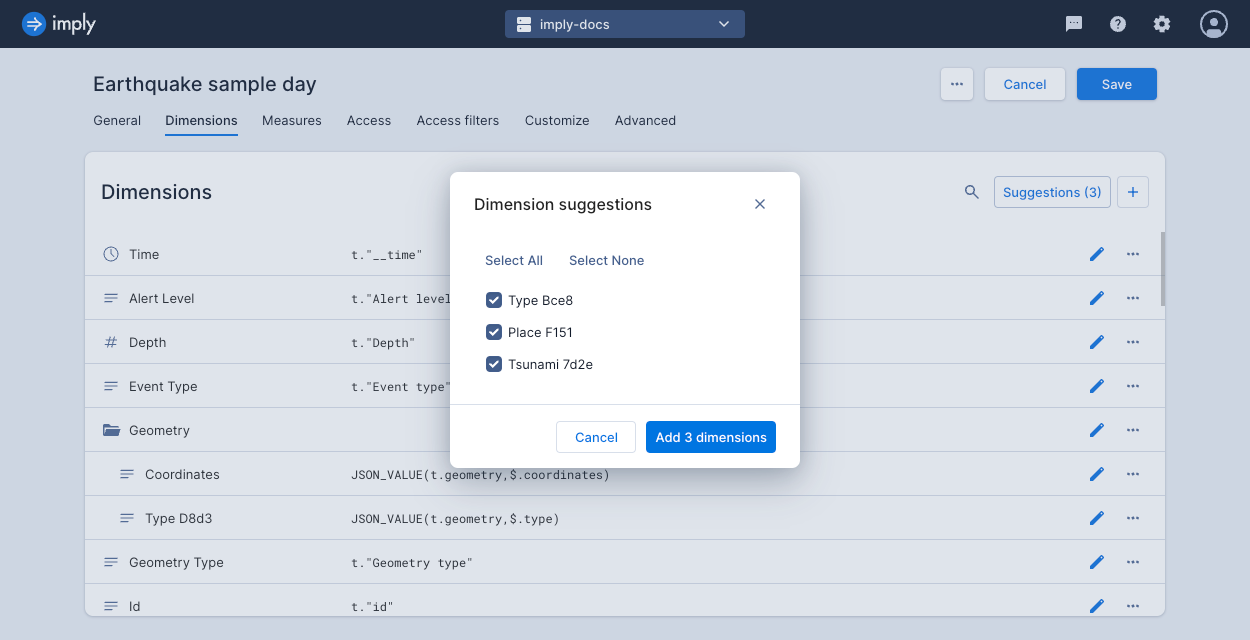
Dimension suggestions
Click Suggestions at the top of the Dimensions page to review and add potential dimensions. Polaris scans the schema that underlies the dataset and automatically suggests dimensions for any columns not already represented.
You can use this feature if you add a new column to an existing table and want to include it in your data cube views.
Dimension types
This section describes the dimension types you can create.
Time dimensions
Druid has a primary time column called __time which it uses for partitioning. You can also create additional time columns.
Druid ingests time columns as regular dimensions formatted in ISO 8601 string format, for example 2017-04-20T16:20:00Z.
When creating or editing a dimension, select Time as the type to configure a time dimension. You can also configure the default granularities that Pivot presents and select a bucketing option.
Pivot uses an algorithm to format time ranges. To override it, go into edit mode for the time dimension and click Format. Enter a specific format to display. For a list of supported formats, see the Moment.js documentation.
The following example datacube shows a time dimension with format ha to display the hour and am/pm in lowercase:
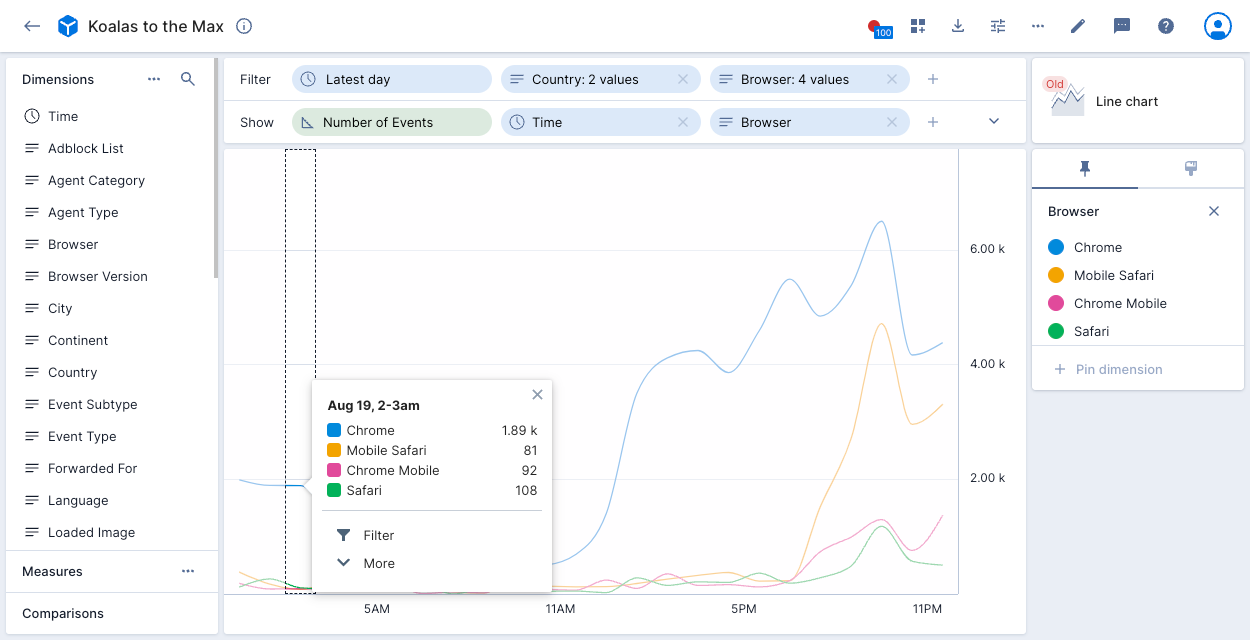
String dimensions
Most dimensions are categorical, in the sense that they are represented as strings. String dimensions appear in the left navigation panel with the "A" icon.
When creating or editing a dimension, select String from the type to make a string dimension.
Multi-value dimensions
Select the Set/String type to create a multi-value dimension, which is an array of strings. For example, a multi-value dimension named Cities might contain the following data:
["Paris","London","New York","Sydney"]
Numeric dimensions
Numeric dimensions represent numeric values in the data source. You can apply aggregations to numeric dimensions to create new measures.
When creating or editing a dimension, select Number from the type to make a numeric dimension. You can also configure the preset bucketing granularities that will be presented as defaults.
Geographic dimensions
Geographic units can be a useful way to segment data.
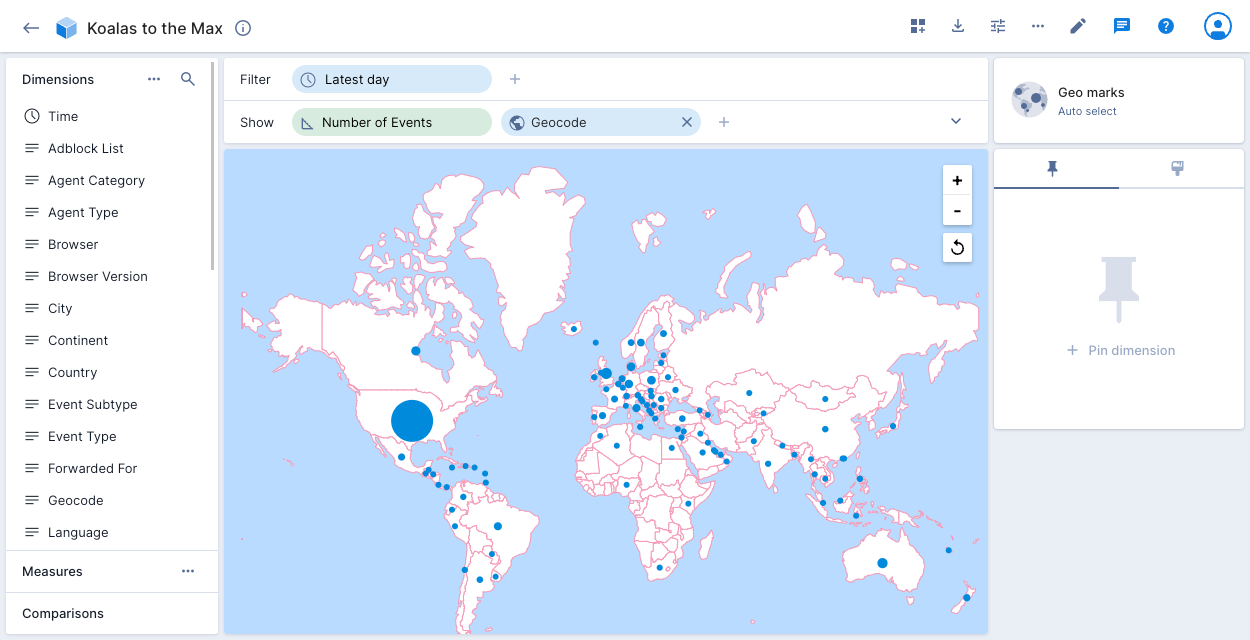
To use the Geo marks and Geo shade visualizations, create and display a single dimension configured as the Geo type. Select the appropriate Geo encoding—the underlying data must conform to one of the following specifications:
Latitude and longitude
If your event data contains latitude and longitude coordinates, you can configure the Street map visualization to pinpoint events to precise locations on a map.
Create dimensions for your latitude and longitude data. Select the Geo type and the latitude or longitude Geo encoding.
See Street map for information on configuring the street map visualization.
Boolean dimensions
You can use boolean expressions to create dimension values. In the following example, you use a formula to create dimensions for accounts in the United States and specific accounts by name.
t.country = 'United States' OR t.accountName IN ('Toyota', 'Honda')
IP dimensions
You can store a dimension as a complex data type representing an IP address or an IP prefix.
When you ingest IP data, you can use the IP and IP prefix type dimensions in Polaris to search and filter in your visualizations based on IP addresses and IP prefixes.
When you create a data cube, Polaris auto-detects the complex IP columns and applies the appropriate type:
- IP: An IP address in a 128-bit binary format.
- IP prefix: An IP prefix in a 136-bit binary format, comprised of a 128-bit address and an 8-bit prefix value.
See the Visualize data page for information on using IP dimensions to filter a visualization.
If you create a dimension with type IP or IP prefix on a column that doesn't contain complex IP type data, Polaris converts the dimension type to string. IP filters don't work on strings but you can apply string filters to this data.
Custom dimension examples
The following formula defines a dimension based on a lookup function for country names:
COALESCE(LOOKUP(t."Country", 'store_sales_country_to_iso31661'), t."Country")
This expression performs a lookup that retrieves the country name based on a mapping between country abbreviations and a country name in the store_sales_country_to_iso31661 table. The resulting data cube includes a dimension with the full country name. In effect, this data cube joins rows from the store_sales_country_to_iso31661 and store_sales tables.
The following examples contain common dimension patterns and show expressions as Pivot SQL.
Lookups
You can create dimensions that perform a lookup at query time. To have a dimension that represents a key into another table, set up a Druid query-time lookup (QTL).
You can then use the LOOKUP() function, passing the lookup key and the lookup table name, as follows:
LOOKUP(t.lookupKey, 'my_awesome_lookup')
To handle values that are not found in the lookup table, you can either retain values that were not found as they are or replace them with a specific string.
For example, to keep values as they are, use the lookup key as the fallback value:
COALESCE(LOOKUP(t.lookupKey, 'my_awesome_lookup'), t.lookupKey)
To replace values not found in the lookup table with a string, such as the word missing, pass the string as the fallback value:
COALESCE(LOOKUP(t.lookupKey, 'my_awesome_lookup'), 'missing')
$lookupKey.lookup('my_awesome_lookup').fallback('missing')
Joins
You can create a dimension that performs a join on another table at query time. When you define a dimension, use the PIVOT_LEFT_JOIN function to enable Polaris to perform a lookup-style (left) join on an arbitrary table.
The function syntax is as follows:
PIVOT_LEFT_JOIN(
t.lookupKey OR ARRAY [expr1, expr2,...],
'my_lookup_table',
'key_column' OR ARRAY [expr1, expr2,...],
'value_column'
)
The first argument is a SQL expression or array of expressions representing the lookup key. The third argument must be a string literal or an array of string literals representing the key column. If you use arrays they must have the same length.
The following example demonstrates a lookup for customer status:
PIVOT_LEFT_JOIN(
t.customerId,
'customer_statuses',
'id',
'status'
)
The following example performs a lookup for value Foxtrot in the nato_phonetic table.
The ['city', 'state'] array in the third argument represents the key column in nato_phonetic.
PIVOT_LEFT_JOIN(
ARRAY ["cityName", "stateName"],
'nato_phonetic',
ARRAY ['city', 'state'],
'Foxtrot'
)
URL dimensions
A URL dimension represent URLs in the source data. You can add a URL transformation to the dimension configuration to have a Go to URL action button for the dimension.
To create a URL dimension, edit the dimension and click Format as URL. Provide the URL pattern, as in this example:
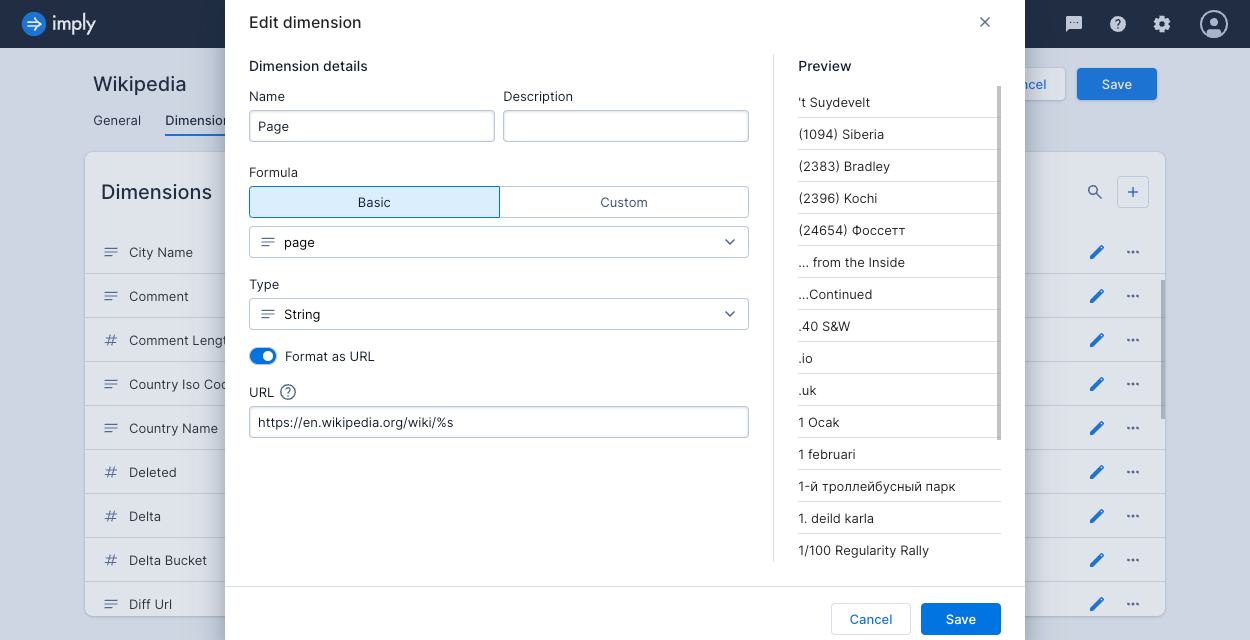
Polaris interpolates the string (%s) for the given dimension value.
In this example, the value Nepal becomes https://en.wikipedia.org/wiki/Nepal, the Wikipedia page for Nepal.
Extractions
Imagine you have a column called resourceName with the following values:
druid-0.18.2
druid-0.18.1
druid-0.17.0
index.html
You can create a dimension that extracts the version number in the column values:
REGEXP_EXTRACT(t.resourceName, '(\d+\.\d+\.\d+)')
Which returns the following values:
0.18.2
0.18.1
0.17.0
null
Other examples
This section includes common expressions you can use to build custom dimensions from the dimensions that already exist in your data cube.
This example returns the character length for every row of the dimension. Applies to the String dimension type.
LENGTH(t."comment")
This example extracts all numbers from every row of the dimension. If there are no numbers, it returns missing. Use regex expressions to build extractions. Applies to the String dimension type.
(REGEXP_EXTRACT(t."comment", '([0-9]+)', 0))
This example makes the entire string upper case. The function also accepts 'lowerCase'. Applies to the String dimension type.
UPPER(t."comment")
This example adds 'End of String' to the end of the dimension's values. Applies to the String dimension type.
CONCAT(t."comment", 'End of String')
This example returns the index value for 'World' in the string for every row in the dimension. In Pivot SQL, the function starts indexing at 1 and returns 0 when no match is found. Applies to the String dimension type.
POSITION('World' IN t."dimension") - 1
This example returns x-y number of characters for every row in the dimension. Applies to the String dimension type.
SUBSTR(t."dimension", x, y)
This example returns true if the value matches a value in the specified set; otherwise, returns false.
You can specify the returned values as follows:
$cityName.in(['London','Aachen','Abbotsford']).then('Match Found').fallback('No Match')
Applies to String and Numeric data types.
t."cityName" IN ('London','Aachen','Abbotsford')
This example returns true or false based on whether the given regular expression is matched. You can specify the returned values as follows:
$dimension.match('^Hel*')then('Matched').fallback('Not matched')
Applies to the String dimension type.
REGEXP_LIKE(t."comment", ('^Hel*'))
This example returns true or false based on whether the input string is matched. You can specify the returned values like this: $dimension.contains('hello').then('Hello Friend').fallback('Bye Friend')
Applies to the String dimension type.
CONTAINS_STRING(t."comment", 'hello')
You can use math operations in custom expressions. Applies to the Numeric data type.
LENGTH(f."comment") + 2
This example returns an absolute value. Applies to the Numeric data type.
ABS(CHAR_LENGTH(t."channel")-100)
This example raises the operand to the power that you specify. Applies to the Numeric data type.
POWER(LENGTH(t."comment"), 5)
This example returns true if the value matches the input value and false if it does not. Only use single quotes with strings. Applies to String, Numeric, and Boolean data types.
t."comment" IS 'red'
This example performs an AND operation between the value of the dimension and the second value that you input. Additional Boolean expressions include 'or', 'greaterOrEqual', 'greaterThan', 'lessThanOrEqual', 'lessThan', and 'not'. Applies to the Boolean data type.
t."comment" AND (2>1)
This example creates a time bucket of the duration that you specify. Applies to the Time data type.
TIME_FLOOR(t."__time", 'PT5M')
This example returns the largest operand time which is less than or equal to the nearest duration within the specified timezone. Applies to the Time data type.
TIME_FLOOR(t."__time", 'P1D', 'Asia/Shanghai')
This example shifts the operand time by the interval you specify within the given timezone. Do not use a + sign to shift time forward. Applies to the Time data type.
TIME_SHIFT(t."__time", 'PT1M', -5)
This example returns part of a timestamp. Additional possibilities include: 'MINUTE_OF_HOUR', 'MINUTE_OF_DAY', 'MINUTE_OF_WEEK', 'MINUTE_OF_MONTH', 'MINUTE_OF_YEAR', 'HOUR_OF_DAY', 'HOUR_OF_WEEK', 'HOUR_OF_MONTH', 'HOUR_OF_YEAR', 'DAY_OF_WEEK', 'DAY_OF_MONTH', 'DAY_OF_YEAR', 'WEEK_OF_MONTH', 'WEEK_OF_YEAR', and 'MONTH_OF_YEAR'. Applies to the Time data type.
TIME_EXTRACT(t."__time", 'SECOND')
This example casts a number to a time value.
MILLIS_TO_TIMESTAMP(t."dimension")